
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- Object Detection metric
- RPN
- BiFPN
- Faster R-CNN
- fine tune AlexNet
- multi task loss
- Anchor box
- object queries
- detr
- Fast R-CNN
- herbwood
- pytorch
- YOLO
- Object Detection
- Non maximum suppression
- AP
- Map
- Hungarian algorithm
- IOU
- Detection Transformer
- mean Average Precision
- Bounding box regressor
- Region proposal Network
- RoI pooling
- hard negative mining
- Linear SVM
- R-CNN
- Darknet
- Multi-task loss
- Average Precision
- Today
- Total
약초의 숲으로 놀러오세요
Fast R-CNN 논문 리뷰 본문
이번 포스팅에서는 Fast R-CNN 논문(Fast R-CNN)을 읽고 정리해봤습니다. 기존 R-CNN 모델은 학습 시간이 매우 오래 걸리며, detection 속도 역시, 이미지 한 장당 47초나 걸려 매우 느린 추론 속도를 보였습니다. 또한 3가지의 모델(AlexNet, linear SVM, Bounding box regressor)을 독립적으로 학습시켜, 연산을 공유하거나 가중치값을 update하는 것이 불가능하다는 문제도 있습니다. Fast R-CNN은 모델명에서부터 Fast가 붙는만큼 기존 R-CNN 모델보다 속도면에서의 큰 개선을 보인 모델입니다.
Fast R-CNN 모델
Preview
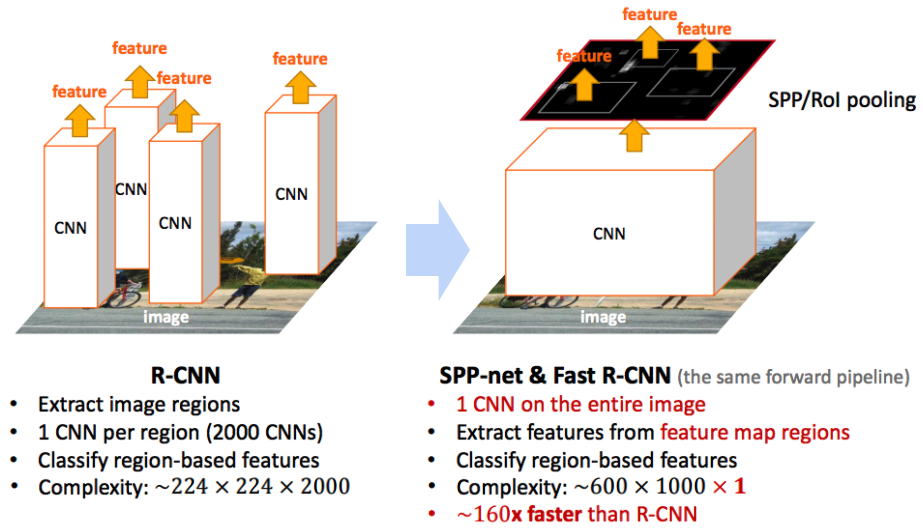
R-CNN 모델은 2000장의 region proposals를 CNN 모델에 입력시켜 각각에 대하여 독립적으로 학습시켜 많은 시간이 소요됩니다. Fast R-CNN은 이러한 문제를 개선하여 단 1장의 이미지를 입력받으며, region proposals의 크기를 warp시킬 필요 없이 RoI(Region of Interest) pooling을 통해 고정된 크기의 feature vector를 fully connected layer(이하 fc layer)에 전달합니다. 또한 multi-task loss를 사용하여 모델을 개별적으로 학습시킬 필요 없이 한 번에 학습시킵니다. 이를 통해 학습 및 detection 시간이 크게 감소하였습니다. 자세한 학습 과정을 살펴보기에 앞서 Fast R-CNN에 도입된 핵심 아이디어들을 살펴보도록 하겠습니다.
Main Ideas
1. RoI(Region of Interest) Pooling
RoI(Region of Interest) pooling은 feature map에서 region proposals에 해당하는 관심 영역(Region of Interest)을 지정한 크기의 grid로 나눈 후 max pooling을 수행하는 방법입니다. 각 channel별로 독립적으로 수행하며, 이 같은 방법을 통해 고정된 크기의 feature map을 출력하는 것이 가능합니다. 구체적인 동작 원리를 살펴보도록 하겠습니다(파란색 글씨는 위의 예제 해설입니다).
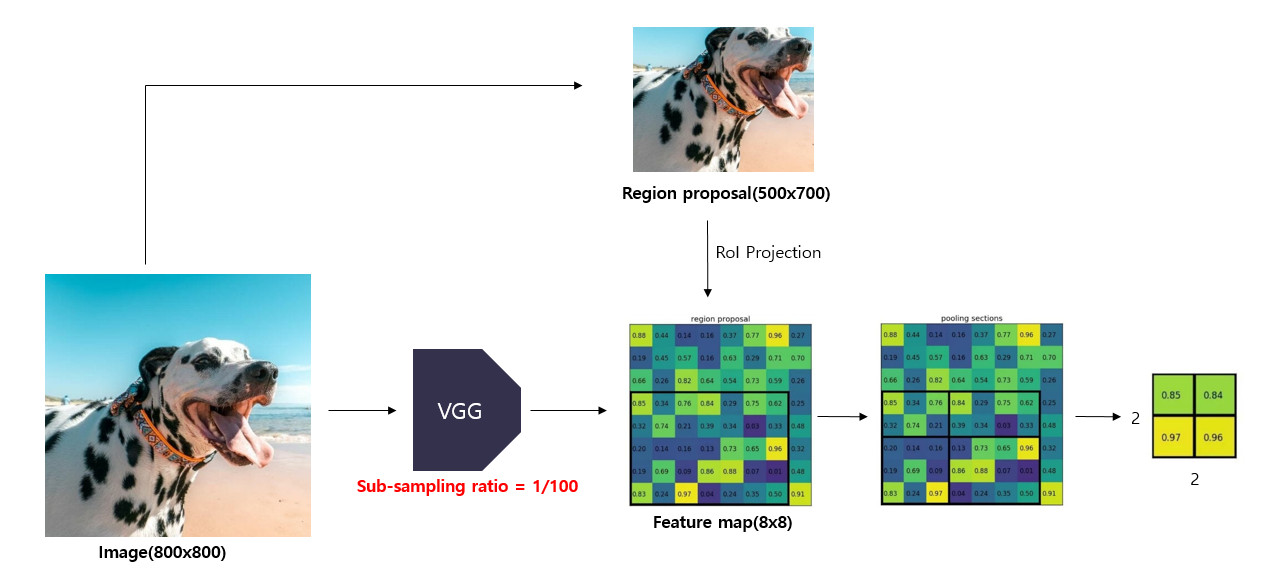
1) 먼저 원본 이미지를 CNN 모델에 통과시켜 feature map을 얻습니다.
- 800x800 크기의 이미지를 VGG 모델에 입력하여 8x8 크기의 feature map을 얻습니다.
- 이 때 sub-sampling ratio = 1/100이라고 할 수 있습니다(여기서 말하는 subsampling은 pooling을 거치는 과정을 의미).
2) 그리고 동시에 원본 이미지에 대하여 Selective search 알고리즘을 적용하여 region proposals를 얻습니다.
- 원본 이미지에 Selective search 알고리즘을 적용하여 500x700 크기의 region proposal을 얻습니다.
3) 이제 feature map에서 각 region proposals에 해당하는 영역을 추출합니다. 이 과정은 RoI Projection을 통해 가능합니다. Selective search를 통해 얻은 region proposals는 sub-sampling 과정을 거치지 않은 반면, 원본 이미지의 feature map은 sub-sampling 과정을 여러 번 거쳐 크기가 작아졌습니다. 작아진 feature map에서 region proposals이 encode(표현)하고 있는 부분을 찾기 위해 작아진 feature map에 맞게 region proposals를 투영해주는 과정이 필요합니다. 이는 region proposal의 크기와 중심 좌표를 sub sampling ratio에 맞게 변경시켜줌으로써 가능합니다.
- Region proposal의 중심점 좌표, width, height와 sub-sampling ratio를 활용하여 feature map으로 투영시켜줍니다.
- feature map에서 region proposal에 해당하는 5x7 영역을 추출합니다.
4) 추출한 RoI feature map을 지정한 sub-window의 크기에 맞게 grid로 나눠줍니다.
- 추출한 5x7 크기의 영역을 지정한 2x2 크기에 맞게 grid를 나눠줍니다.
5) grid의 각 셀에 대하여 max pooling을 수행하여 고정된 크기의 feature map을 얻습니다.
- 각 grid 셀마다 max pooling을 수행하여 2x2 크기의 feature map을 얻습니다.
이처럼 미리 지정한 크기의 sub-window에서 max pooling을 수행하다보니 region proposal의 크기가 서로 달라도 고정된 크기의 feature map을 얻을 수 있습니다.
2. Multi-task loss
Fast R-CNN 모델에서는 feature vector를 multi-task loss를 사용하여 Classifier와 Bounding box regressior을 동시에 학습시킵니다. 각각의 RoI(=region proposal)에 대하여 multi task loss를 사용하여 학습시킵니다. 이처럼 두 모델을 한번에 학습시키기 때문에, R-CNN 모델과 같이 각 모델을 독립적으로 학습시켜야 하는 번거로움이 없다는 장점이 있습니다. multi-task loss는 아래와 같습니다.
$$L(p, u, t^u, v) = L_{cls}(p, u) + \lambda[u \ge 1]L_{loc}(t^u, v)$$
$p = (p0, ....., p_k)$ : (K+1)개의 class score
$u$ : ground truth class score
$t^u = (t_x^u, t_y^u, t_w^u, t_h^u)$ : 예측한 bounding box 좌표를 조정하는 값
$v = (v_x, v_y, v_w, v_h)$ : 실제 bounding box의 좌표값
$L_{cls}(p, u) = -log {p_u}$ : classification loss(Log loss)
$L_loc(t^u, v) = \sum_{i \in \{x,y,w,h \}} smooth_{L_1}(t_i^u - v_i)$ : regression loss(Smooth L1 loss)
$smooth_{L_1}(t_i^u - v_i) = \begin{cases} 0.5x^2, if |x| < 1 \\ |x| - 0.5, otherwise \end{cases}$
$\lambda$ : 두 loss 사이의 가중치를 조정하는 balancing hyperparamter
- K개의 class를 분류한다고할 때, 배경을 포함한 (K+1)개의 class에 대하여 Classifier를 학습시켜줘야 합니다.
- $u$는 positive sample인 경우 1, negative sample인 경우 0으로 설정되는 index parameter입니다.
- L1 loss는 R-CNN, SPPnets에서 사용한 L2 loss에 비행 outlier에 덜 민감하다는 장점이 있습니다.
- $\lambda$=1 로 사용합니다.
- multi task loss는 0.8~1.1% mAP를 상승시키는 효과가 있다고 합니다.
3. Hierarchical Sampling
R-CNN 모델은 학습 시 region proposal이 서로 다른 이미지에서 추출되고, 이로 인해 학습 시 연산을 공유할 수 없다는 단점이 있습니다. 논문의 저자는 학습 시 feature sharing을 가능하게 하는 Hierarchical sampling 방법을 제시합니다. SGD mini-batch를 구성할 때 N개의 이미지를 sampling하고, 총 R개의 region proposal을 사용한다고 할 떼, 각 이미지로부터 R/N개의 region proposals를 sampling하는 방법입니다. 이를 통해 같은 이미지에서 추출된 region proposals끼리는 forward, backward propogation 시, 연산과 메모리를 공유할 수 있습니다.
논문에서는 학습 시, N=2, R=128로 설정하여, 서로 다른 2장의 이미지에서 각각 64개의 region proposals를 sampling하여 mini-batch를 구성합니다. 각 이미지의 region proposals 중 25%(=16장)는 ground truth와의 IoU 값이 0.5 이상인 sample을 추출하고, 나머지(75%, 48장)에 대해서는 IoU 값이 0.1~0.5 사이의 sample을 추출합니다. 전자의 경우 positive sample로, 위에서 정의한 multi-task loss의 $u=1$이며, 후자는 $u=0$인 경우라고 할 수 있습니다.
4. Truncated SVD
Fast R-CNN 모델은 detection 시, RoI를 처리할 때 fc layer에서 많은 시간을 잡아먹습니다. 논문에서는 detection 시간을 감소시키기 위해 Truncated SVD(Singular Vector Decomposition)을 통해 fc layer를 압축하는 방법을 제시합니다. SVD에 대한 설명은 귀퉁이 서재님의 블로그를 참고했습니다.

행렬 $A$를 $m \times m$ 크기인 $U$, $m \times n$ 크기인 $\Sigma$, $n \times n$ 크기인 $V^T$ 로 특이값 분해(SVD)하는 것을 Full SVD(Singular Vector Decomposition)라고 합니다. 하지만 실제로 이처럼 Full SVD를 하는 경우는 드물며, Truncated SVD와 같이 분해된 행렬 중 일부분만을 활용하는 reduced SVD를 일반적으로 많이 사용한다고 합니다.

Truncated SVD는 $\Sigma$의 비대각 부분과 대각 원소 중 특이값이 0인 부분을 모두 제거하고, 제거된 $\Sigma$에 대응되는 $U$, $V$ 원소도 함께 제거하여 차원을 줄인 형태입니다. $U_t$의 크기는 $m \times t$이며, $\Sigma_t$의 크기는 $t \times t$, 그리고 $V^t$의 크기는 $t \times n$입니다. 이렇게 하면 행렬 $A$를 상당히 근사하는 것이 가능합니다.
$$W \approx U\Sigma_tV^T$$
fc layer의 가중치 행렬이 $W(=u \times v)$라고 할 때, Truncated SVD를 통해 위와 같이 근사하는 것이 가능합니다. 이를 통해 파라미터 수를 $u \times v$에서 $t(u + v)$로 감소시키는 것이 가능합니다. Truncated SVD를 fc layer의 가중치 행렬 $W$에 적용하면, fc layer는 두 개의 fc layer로 나눠지게됩니다. 첫 번째 fc layer는 $\Sigma_tV^T$ 가중치 행렬, 두 번째 fc layer는 $U$ 가중치 행렬입니다. 이를 통해 네트워크를 효율적으로 압축하는 것이 가능하며, 논문의 저자는 Truncated SVD를 통해 detection 시간이 30% 정도 감소되었다고 말합니다.
Training Fast R-CNN
이제 본격적으로 Fast R-CNN 모델을 학습시키는 과정을 살펴보도록 하겠습니다. 하나의 이미지가 입력되었을 때를 가정하고 전체 학습 과정을 살펴보도록 하겠습니다.
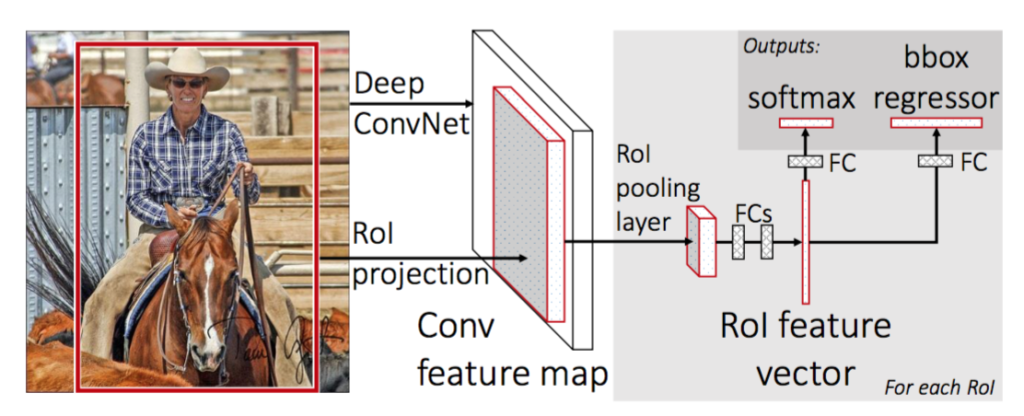
1) Initializing pre-trained network
feature map을 추출하기 위해 VGG16 모델을 사용합니다. 먼저 네트워크를 detection task에 맞게 변형시켜주는 과정이 필요합니다.
1. VGG16 모델의 마지막 max pooling layer를 RoI pooling layer로 대체해줍니다. 이 때 RoI pooling을 통해 출력되는 feature map의 크기인 H, W는 후속 fc layer와 호환 가능하도록 크기인 7x7로 설정해줍니다.
2. 네트워크의 마지막 fc layer를 2개의 fc layer로 대체합니다. 첫 번째 fc layer는 K개의 class와 배경을 포함한 (K+1)개의 output unit을 가지는 Classifier이며, 두 번째 fc layer는 각 class별로 bounding box의 좌표를 조정하여 (K+1) * 4개의 output unit을 가지는 bounding box regressor입니다.
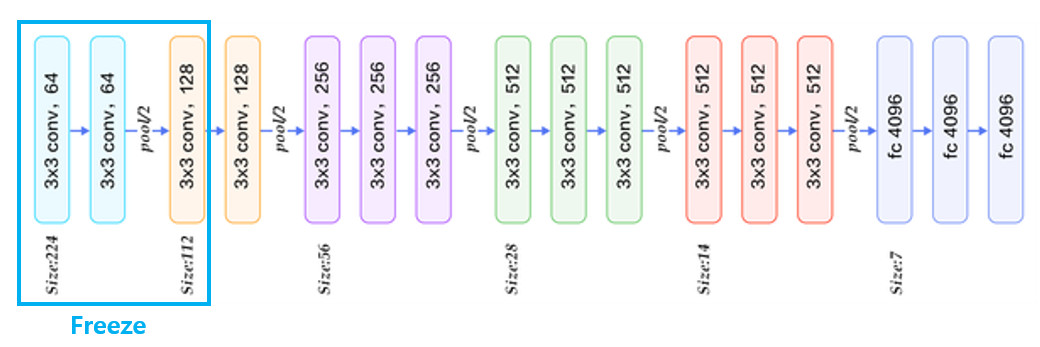
3. conv layer3까지의 가중치값은 고정(freeze)시켜주고, 이후 layer(conv layer4~ fc layer3)까지의 가중치값이 학습될 수 있도록 fine tuning해줍니다. 논문의 저자는 fc layer만 fine tuning했을 때보다 conv layer까지 포함시켜 학습시켰을 때 더 좋은 성능을 보였다고 합니다.
4. 네트워크가 원본 이미지와 selective search 알고리즘을 통해 추출된 region proposals 집합을 입력으로 받을 수 있도록 변환시켜 줍니다.
2) region proposal by Selective search
먼저 원본 이미지에 대하여 Selective search 알고리즘을 적용하여 미리 region proposals를 추출합니다.
- Input : image
- Process : Selective search
- Output : 2000 region proposals
3) Feature extraction(~layer13 pre-pooling) by VGG16
VGG16 모델에 224x224x3 크기의 원본 이미지를 입력하고, layer13까지의 feature map을 추출합니다. RoI pooling 과정은 바로 다음 단계에서 살펴보고, 이번 단계에서는 VGG16을 통해 추출된 feature map까지만 짚고 넘어가도록 하겠습니다. 마지막 pooling을 수행하기 전에 14x14 크기의 feature map 512개가 출력됩니다.
- Input : 224x224x3 sized image
- Process : feature extraction by VGG16
- Output : 14x14x512 feature maps
4) Max pooling by RoI pooling

region proposals를 layer13을 통해 출력된 feature map에 대하여 RoI projection을 진행한 후, RoI pooling을 수행합니다. 앞서 언급했듯이, RoI pooling layer는 VGG16의 마지막 pooling layer를 대체한 것입니다. 이 과정을 거쳐 고정된 7x7 크기의 feature map을 추출합니다.
- Input : 14x14 sized 512 feature maps, 2000 region proposals
- Process : RoI pooling
- Output : 7x7x512 feature maps
5) Feature vector extraction by Fc layers
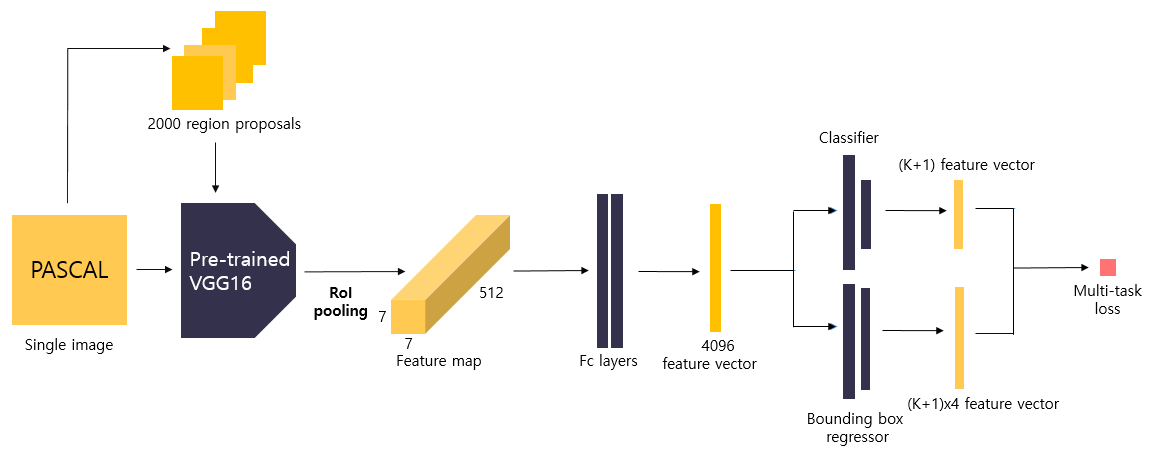
다음으로 region proposal별로 7x7x512(=25088)의 feature map을 flatten한 후 fc layer에 입력하여 fc layer를 통해 4096 크기의 feature vector를 얻습니다.
- Input : 7x7x512 sized feature map
- Process : feature extraction by fc layers
- Output : 4096 sized feature vector
6) Class prediction by Classifier
4096 크기의 feature vector를 K개의 class와 배경을 포함하여 (K+1)개의 output unit을 가진 fc layer에 입력합니다. 하나의 이미지에서 하나의 region proposal에 대한 class prediction을 출력합니다.
- Input : 4096 sized feature vector
- Process : class prediction by Classifier
- Output : (K+1) sized vector(class score)
7) Detailed localization by Bounding box regressor
4096 크기의 feature vector를 class별로 bounding box의 좌표를 예측하도록 (K+1) x 4개의 output unit을 가진 fc layer에 입력합니다. 하나의 이미지에서 하나의 region proposal에 대한 class별로 조정된 bounding box 좌표값을 출력합니다.
- Input : 4096 sized feature vector
- Process : Detailed localization by Bounding box regressor
- Output : (K+1) x 4 sized vector
8) Train Classifier and Bounding box regressor by Multi-task loss
Multi-task loss를 사용하여 하나의 region proposal에 대한 Classifier와 Bounding box regressor의 loss를 반환합니다. 이후 Backpropagation을 통해 두 모델(Classifier, Bounding box regressor)을 한 번에 학습시킵니다.
- Input : (K+1) sized vector(class score), (K+1) x 4 sized vector
- Process : calculate loss by Multi-task loss function
- Output : loss(Log loss + Smooth L1 loss)
Detection Fast R-CNN

다음으로 실제 detection 시, Fast R-CNN 모델의 동작을 살펴보도록 하겠습니다. Detection 시 동작 순서는 학습 과정과 크게 다르지 않습니다. 하지만 4096 크기의 feature vector를 출력하는 fc layer에 Truncated SVD를 적용한다는 점에서 차이가 있습니다. 또한 예측한 bounding box에 대하여 Non maximum suppression 알고리즘이 추가되어 최적의 bounding box만을 출력하게 됩니다.
지금까지 Fast R-CNN 모델에 대해 살펴봤습니다. Fast R-CNN 모델은 R-CNN 모델보다 학습 속도가 9배 이상 빠르며, detection 시, 이미지 한 장당 0.3초(region proposals 추출 시간 포함)이 걸립니다. PASCAL VOC 2012 Challenge에서 mAP 값이 66%를 보이면서 detection 성능 역시 R-CNN 모델에 비해 향상된 모습을 보입니다. 이외에도 multi-task loss를 사용하여 single stage로 여러 모델을 학습시킬 수 있다는 점과, 학습으로 인해 네트워크의 가중치값을 Backpropagation을 통해 update할 수 있다는 장점이 있습니다.
이전 포스팅에서 살펴본 Overfeat의 핵심 아이디어가 fc layer가 고정된 크기의 feature vector를 입력받으니까 그냥 conv layer로 대체해버리자! 였다면, Fast R-CNN 논문에서는 새로운 pooling 방식을 도입하여 fc layer에 고정된 크기의 feature vector를 제공하는 방법을 제시했습니다. 이러한 접근법의 차이가 상당히 흥미로웠습니다. Fast R-CNN 모델을 pytorch로 구현한 코드에 대한 설명은 Pytorch로 구현한 Fast R-CNN 모델 포스팅을 참고하시기 바랍니다. 다음 포스팅에서는 Faster R-CNN 논문을 읽고 리뷰해보도록 하겠습니다.




