
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- hard negative mining
- Hungarian algorithm
- IOU
- multi task loss
- RoI pooling
- YOLO
- Bounding box regressor
- Faster R-CNN
- Multi-task loss
- Linear SVM
- AP
- mean Average Precision
- Anchor box
- object queries
- Detection Transformer
- Region proposal Network
- fine tune AlexNet
- RPN
- Object Detection metric
- BiFPN
- Fast R-CNN
- R-CNN
- Darknet
- Non maximum suppression
- pytorch
- herbwood
- Average Precision
- detr
- Object Detection
- Map
- Today
- Total
약초의 숲으로 놀러오세요
Overfeat 논문(Integrated Recognition, Localization and Detectionusing Convolutional Networks) 리뷰 본문
Overfeat 논문(Integrated Recognition, Localization and Detectionusing Convolutional Networks) 리뷰
herbwood 2020. 12. 4. 20:12이번 포스팅에서는 Overfeat(Integrated Recognition, Localization and Detectionusing Convolutional Networks) 논문을 읽고 정리해봤습니다. 이전에 읽었던 R-CNN 논문에서 Overfeat보다 R-CNN이 더 좋은 성능을 보였다는 언급이 있어, 굳이 Overfeat을 공부해야할까 고민했지만, 논문을 직접 읽고 생각이 달라졌습니다. 논문에서 다른 detection 모델과는 다른 구조나 학습 방법 등 새로운 시도가 있어 흥미로웠습니다. 실제로 이러한 접근 방법은 One-stage detector의 시초로서의 면모를 보이며, SSD, YOLO 등 후속 모델에 큰 영향을 주었다고 합니다. Overfeat을 공부하면서 cogneethi님의 블로그와 youtube 강의에서 많은 도움을 받았습니다.
Intuition
Overfeat 모델의 전체적인 동작 원리는 R-CNN 모델과 유사합니다. Feature extractor로부터 feature map을 추출하고, 이를 Classifier와 Bounding box regressor가 입력받아 각각 class 및 confidence score와 bounding box의 좌표를 반환합니다. 하지만 이를 학습시키고 추론하는 과정에서의 접근 방식에서 차이가 있습니다. 이러한 점에서 개인적으로 이해하기에 조금 어려운 방식들이 있었기에, 이 부분부터 짚고 넘어가도록 하겠습니다.
1) Multi-scale input
먼저 Overfeat 모델은 detection시, multi-scale 이미지를 입력받습니다. detection 모델이 하나의 이미지를 다양한 크기로 입력받으면 이미지 내 존재하는 다양한 크기의 객체를 보다 쉽게 포착하는 것이 가능해집니다. 실제로 이미지의 scale이 커지면 더 작은 객체를 탐지하는 것이 가능합니다. 이러한 점은 기존 CNN 모델이 고정된 크기의 이미지(single-scale)를 입력받는다는 점에서 차이를 보입니다. 가령 AlexNet 모델은 227x227, VGG 모델은 224x224 크기의 이미지를 입력으로 받습니다. Detection 모델인 R-CNN 모델 역시 Selective search로 추출한 region proposal을 fine tuned된 AlexNet에 입력하기 위해 227x227 크기로 warp 시킵니다. 이처럼 CNN 모델이 고정된 크기의 이미지를 입력받는 이유는 fc layer(fully connected layer)가 고정된 크기의 feature vector를 입력받기 때문입니다.

이미지의 scale이 변하면 fc layer에 입력되는 feature vector의 크기 역시 변하기 때문에, 일반적인 CNN 모델은 다양한 크기의 이미지를 입력으로 받을 수 없습니다. 하지만 fc layer를 conv layer로 대체하면 다양한 크기의 이미지를 입력받을 수 있습니다. Overfeat 모델은 이러한 점을 착안하여 모델의 fc layer를 conv layer로 대체합니다. 하지만 이로 인해 output은 이미지 scale에 따라 가변적인 크기를 가지게 됩니다. 이처럼 scale에 따라 다른 크기를 가진 output map은 object detection task에서 어떤 의미를 가질까요?
2) Spatial outputs
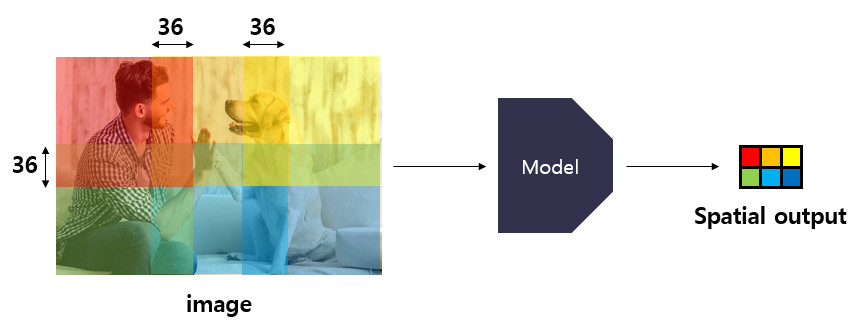
논문의 저자는 output map의 크기가 1x1(width x height)인 경우를, Non-spatial하다고 간주합니다. 일반적인 CNN 모델이 fc layer를 통해 최종 예측으로 1x1x(class 수) 크기의 output을 산출하는 경우, 이는 non-spatial하다고 볼 수 있습니다. 반면에 Overfeat 모델은 detection 시, 입력 이미지의 scale에 따라 conv layer를 통해 2x3, 3x5, 5x7, 6x7, 7x10과 같은 다양한 크기의 output map을 산출합니다. 이같은 경우는 Spatial output이라고 할 수 있습니다.

위의 그림을 보면 4x4, 8x8 크기의 이미지가 있습니다. 2x2 Pooling(stride=2) layer를 두 차례 거쳐 서로 다른 크기의 output을 산출합니다. 4x4 크기의 이미지는 1x1 크기의 output map(non-spatial output)을 가집니다. 여기서 1x1 output map은 4x4 크기의 이미지에 대한 정보를 encode합니다. 이처럼 1x1 크기의 pixel이 encode하는 범위를 receptive field라고 합니다. 8x8 크기의 이미지는 2x2 크기의 output map(spatial output)을 가집니다. 그렇다면 2x2 크기의 output map에서 각 pixel들은 어떤 대상을 표현한 것일까요? 2x2 spatial map의 좌상단 요소(빨간색)는 두 차례의 pooling을 거쳤지만 결국 8x8 크기의 원본 이미지에서 좌상단 4x4 크기만큼의 receptive field를 encode한다고 볼 수 있습니다.
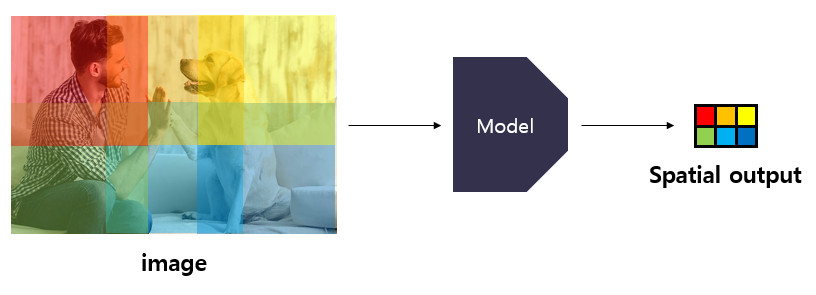
즉, 모델에 의한 산출된 spatial output의 한 요소는 원본 이미지 내 특정 receptive field에 대한 정보를 encode하고 있다고 볼 수 있습니다. 이러한 정보는 학습 방법에 따라 특정 class의 confidence score나 bounding box의 좌표값이 될 수 있습니다. 위의 그림에서 spatial output의 각 요소는 색깔에 맞는 이미지의 영역에 대한 정보를 함축하고 있다고 볼 수 있습니다.

위의 그림을(출처 : cogneethi님의 블로그) 보면 6개 scale의 이미지를 모델에 입력시켜 얻은 서로 다른 크기의 spatial output이 있으며, 각 요소가 원본 이미지의 어떤 영역을 encode하는지 잘 나타나 있습니다. 저는 직관적으로 spatial map의 한 요소는 압축된 bounding box와도 같다고 받아들였습니다. 실제로 2x3 크기의 spatial output이 산출되면 이는 이미지 내에서 총 6개의 객체를 탐지할 수 있음을 의미합니다. 저는 개인적으로 spatial map에 대한 직관적인 이해가 정말 중요하며, Overfeat 논문을 읽어나가는데 도움이 된다고 생각합니다.
3) ConvNets Sliding Window Efficiency
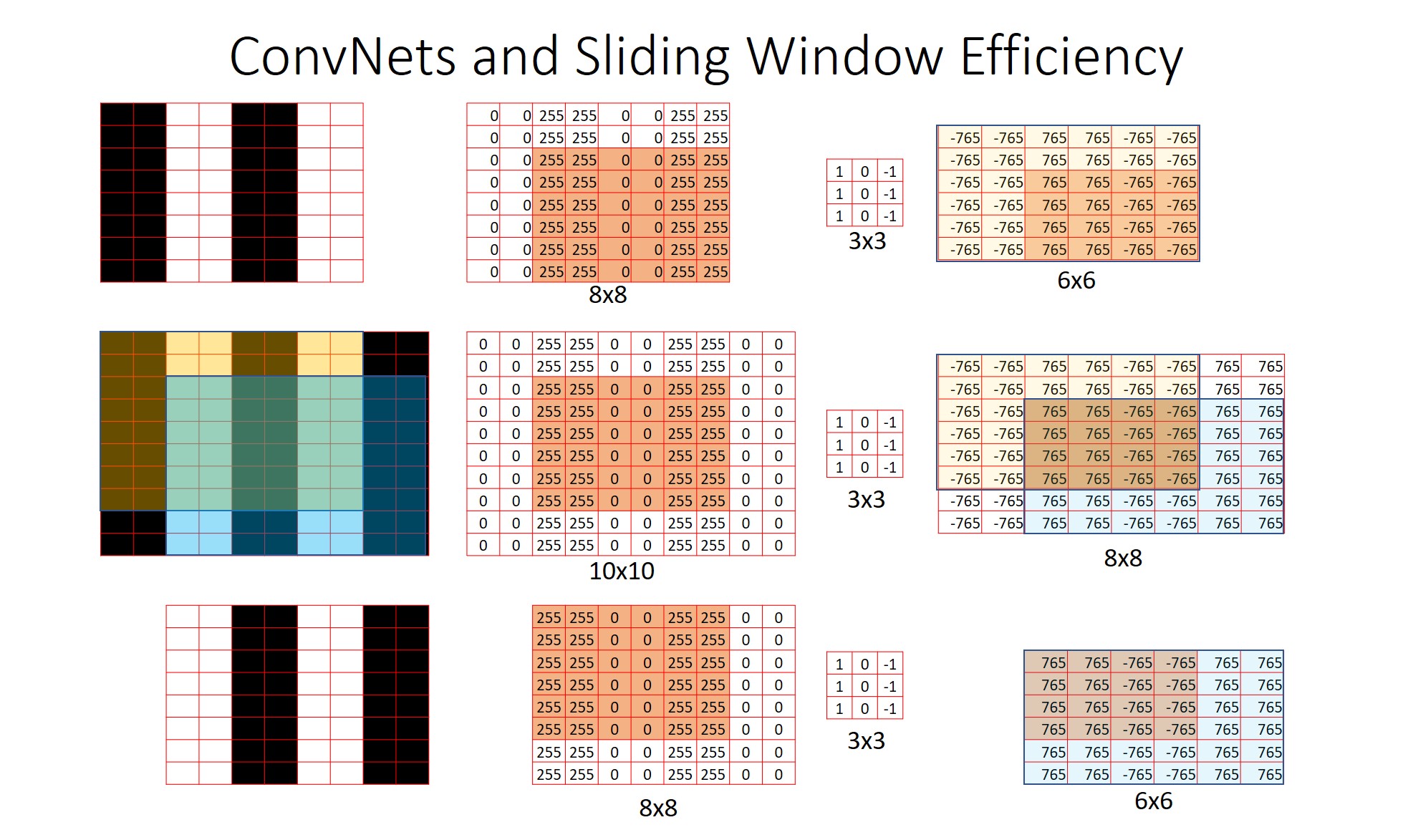
feature map에 conv filter를 적용하여 전체를 순회하는 과정은 sliding window와 유사합니다. 하지만 논문의 저자는 fc layer를 conv layer로 대체함으로써 Sliding window와 같은 효과를 보다 효율적으로 구현할 수 있었다고 말합니다. Conv layer에서 conv filter를 적용하는 과정에서 자연스레 겹치는 영역끼리 연산을 공유하기 때문입니다. 위의 그림을 보면 노란색 영역과 파란색 영역에 대하여 3x3 conv filter를 적용한 결과 겹치는 영역에 대한 정보가 같습니다. 이는 conv layer에서 겹치는 영역에 대한 중복된 연산을 피할 수 있음을 의미합니다. 반면에 Sliding window 방식을 통해 window 크기만큼 crop된 이미지 영역을 입력받으면, 각 window가 독립적이기 때문에 불필요한 연산이 발생할 수 있습니다.
지금까지 Overfeat 논문을 읽으면서 직관적으로 이해하고 넘어가면 좋은 부분을 정리해봤습니다. 이제는 본격적으로 Overfeat 모델의 구조와 학습 및 추론 방법에 대해 살펴보도록 하겠습니다.
Overfeat 모델

Overfeat 모델은 detection 시, 다음과 같은 순서에 따라 동작합니다.
- 6-scale 이미지를 입력받습니다.
- Classification task 목적으로 학습된 Feature extractor에 이미지를 입력하여 feature map을 얻습니다.
- Feature map을 Classifier와 Bounding box regressor에 입력하여 spatial map을 출력합니다.
- 예측 bounding box에 Greedy Merge Strategy 알고리즘을 적용하여 예측 bounding box를 출력합니다.
Overfeat 모델은 Classification, Localization, Detection task에 모두 사용할 수 있습니다. Overfeat을 Classification task를 위해 학습시킨 후, fc layer를 제거하여 feature extractor로 활용하여 localization, detection task에 사용될 수 있습니다. 먼저 Overfeat 모델을 Classification task를 해결하기 위해 학습시키는 방법부터 살펴보도록 하겠습니다.
1) Overfeat for Classification Task
Training Overfeat
Overfeat 모델은 AlexNet 모델과 유사하지만 contrast normalization을 사용하지 않으며, pooling 시 겹치는 영역이 없도록(non-overlapping)한 점, 그리고 더 작은 stride(4 대신 2)를 적용하여 1,2번째 layer의 feature map이 더 크다는 차이가 있습니다. ImageNet 데이터를 통해 1000개의 class를 예측하도록 학습시킵니다. 논문의 저자는 모델 설계 방식에 따라 더 빠르게 동작하는 fast mode와, 정확도가 더 높은 accurate mode를 발표합니다. 모델의 구조는 위와 같습니다.
2) Overfeat for Localization/Detection task
Localization/Detection task 시에는, Classification task를 위해 학습된 Overfeat 모델에서 layer5까지만 사용하고 나머지 layer는 fine tuning합니다. 먼저 detection task 시, class를 분류하는 Classifier의 학습 방법에 대해서 살펴보겠습니다.
1. Training Classifier
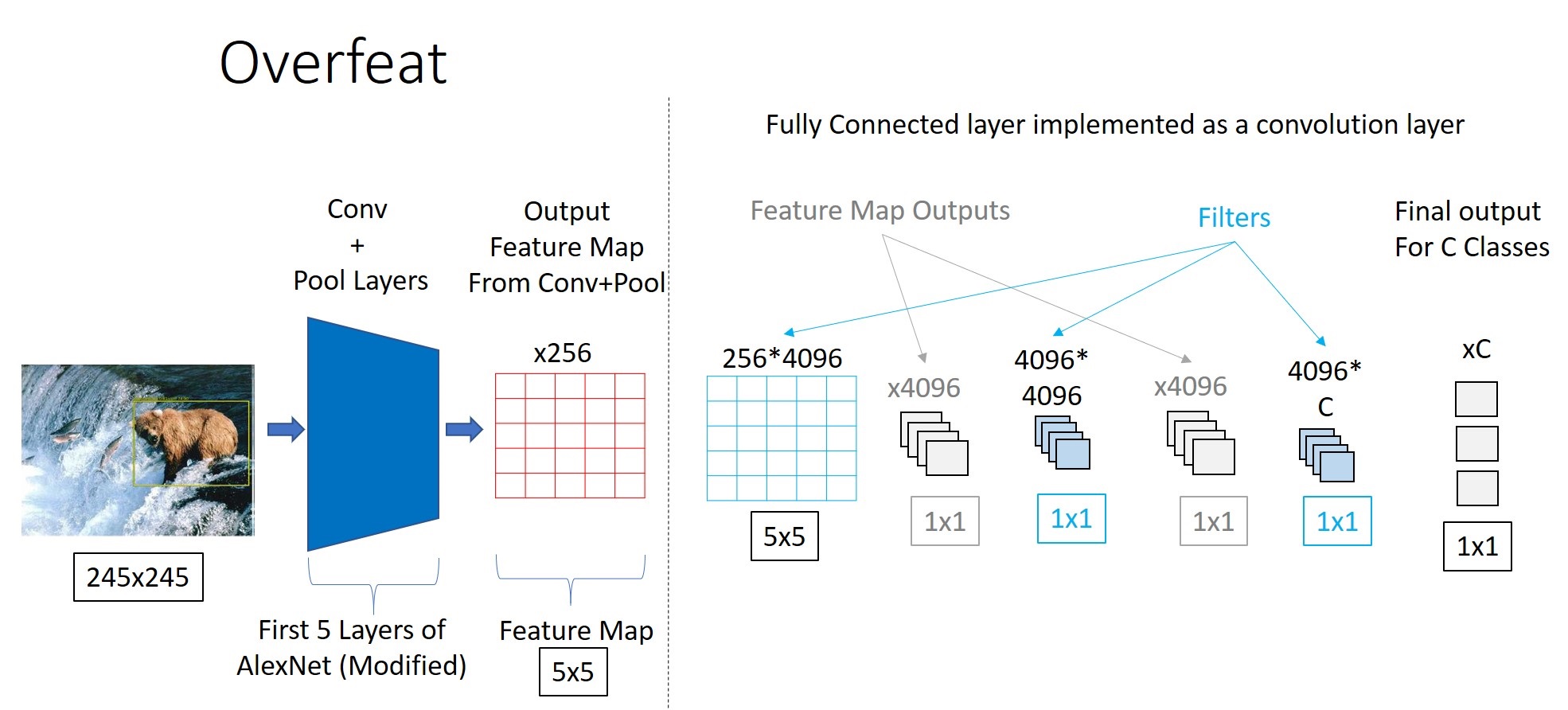
Classifier를 학습시키는 과정은 크게 어렵지 않습니다. 앞서 언급했다시피 Overfeat은 detection task시, multi-scale 이미지를 입력받고, 이를 통해 얻은 spatial output을 활용하여 detection을 수행합니다. 따라서 feature extractor 뒤에 fc layer 대신, conv layer를 추가해줘야합니다. 학습 시에는 하나의 scale의 이미지만을 사용합니다. Detection task를 위한 Classifier의 학습 과정은 아래와 같습니다.
1) Classification task를 위해 미리 학습시킨 Overfeat 모델을 layer5까지만 불러와 feature extractor로 사용하고 layer6(5x5 conv, 4096), layer7(1x1 conv, 4096x4096), layer8(1x1, 4096xC)를 추가합니다.
2) 이미지를 feature extractor(~layer5)에 입력하여 5x5 크기의 feature map을 256개를 출력합니다.
3) 5x5 크기의 feature map을 layer 6,7,8에 입력하여 1x1xC 크기(C = class의 수)의 feature map을 출력합니다.
4) loss function(softmax)을 통해 학습시킵니다.
Classifier는 학습 과정과 inference 과정에서 동작 시 차이가 있습니다. 학습시킨 Classifier가 inference(=detection) 시, 어떤 과정을 거쳐 동작하는지 구체적으로 살펴보겠습니다.
2. Inference by Classifier
Detection task 시, Classifier가 동작하는 순서를 살펴보기에 앞서, 논문의 저자가 모델에 충분한 view를 제공하기 위해 고안한 새로운 pooling 방법을 살펴보도록 하겠습니다.
Resolution Augmentation
논문의 저자는 Classifier가 inference 시, 충분한 view를 제공하기 위한 새로운 pooling 방법을 제시합니다. 이미지가 CNN 모델의 여러 pooling layer를 거치면 subsampling 되어 작은 크기의 feature map으로 변합니다. 만약 CNN 모델의 subsampling ratio, 즉 pooling된 배수가 36(2x3x2x3)이라면, 마지막 layer의 output feature map의 1 pixel이 36 pixel을 encode하게 됩니다. 논문의 저자는 이같이 마지막 feature map이 원본 이미지에 표현하는 해상도가 너무 포괄적이게 되면 객체와 feature map 사이의 정렬(align)이 맞지 않아, 모델의 성능이 크게 떨어진다고 합니다.
이러한 feature map을 spatial output이라고 할 때, spatial output의 한 요소가 원본 이미지의 지나치게 넓은 receptive field를 표현하면 오히려 객체를 제대로 포착하지 못한다고 이해할 수 있습니다. 논문의 저자는 이를 해결하기 위해, pooling을 수행하는 좌표에서 shift하여 추가적인 pooling을 수행하는 방법을 제시합니다. 논문의 저자는 이를 해결하기 위해 feature map pixel offset {0,1,2}의 조합에 따라, 총 9회의 3x3 max pooling(non-overlapping)을 수행하는 특수한 pooling 방법을 제시합니다.
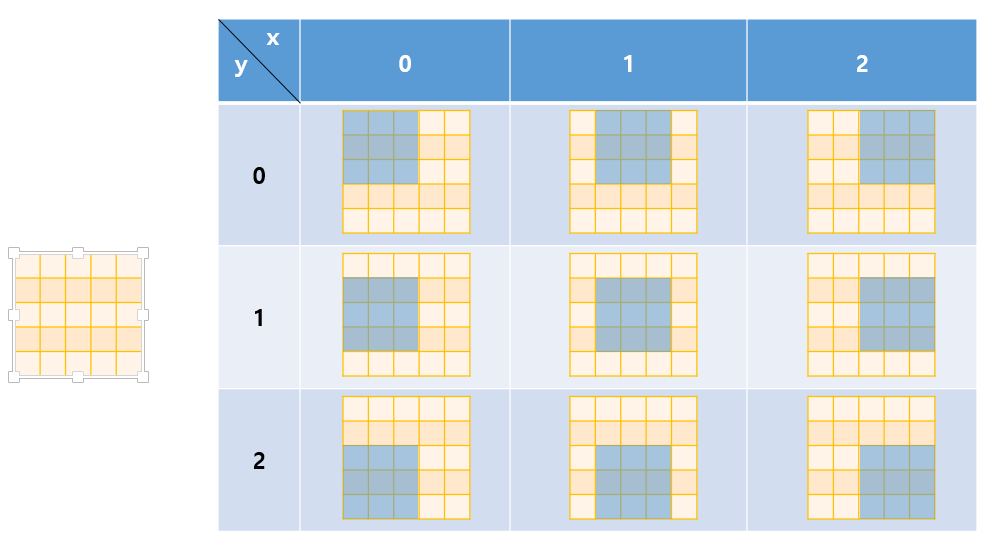
여기서 말하는 pixel offset의 조합은 pooling을 수행하는 기준 좌표에서 x,y 방향으로 {0,1,2}만큼 shift한 좌표의 조합을 의미합니다. 즉 x,y가 shift한 정도의 조합에 따라 3x3((0, 0),(1, 0), (2, 0), (1, 0), (1, 1), (1, 2), (2, 0), (2, 1), (2, 2))개 만큼의 pooling을 수행합니다. 이는 논문의 저자가 정의한 pooling layer에 하나의 feature map이 입력되었을 때 하나의 feature map이 출력되는 것이 아니라, 9개의 feature map이 출력되는 것을 의미합니다.
Inference
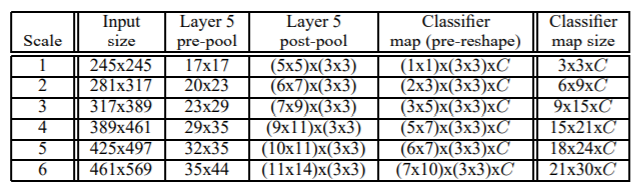
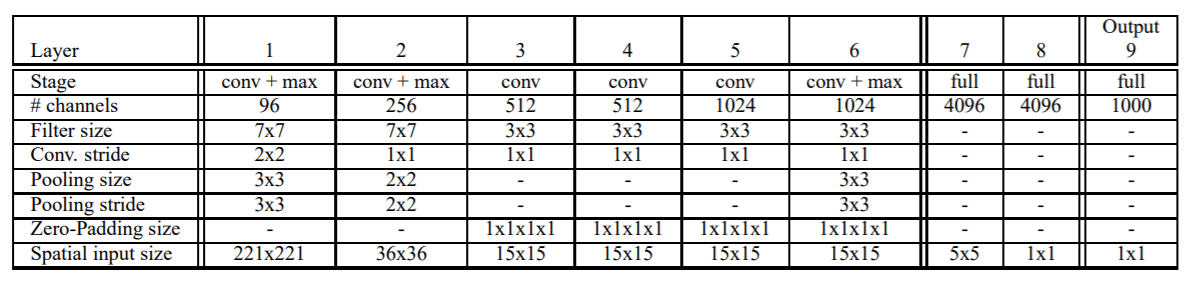
다음으로 detection task 시, Classifier가 동작하는 순서를 살펴보도록 하겠습니다. Detection을 수행하기 때문에 6개의 scale의 이미지를 입력으로 받습니다. 위의 표는 이미지의 scale에 따른 각 layer의 출력 feature map의 크기를 보여주고 있습니다. 여기서 짚고 가야할 점은 scale 1, 즉 245x245 크기의 이미지가 입력되었을 때 spatial output의 크기(width, height)가 1x1이 되는 것으로 보아, receptive field의 크기는 245x245라는 것입니다. 즉, 모든 scale의 spatial output의 한 pixel은 245x245 크기의 receptive field에 대한 정보를 표현하고 있습니다.
표를 좀 더 구체적으로 살펴보겠습니다. 예를 들어 scale 2 이미지(281x317)가 입력되었을 때 논문의 저자가 정의한 pooling이 적용되기 전까지의 feature map의 크기는 20x23입니다. 표에는 나와있지 않지만 feature channel = 256입니다(즉, 20x23x256). pooling을 거친 후 feature map의 크기는 (6x7) pixel offset 조합에 따라 feature map의 수가 3x3배만큼 늘어나기에 output map의 크기는 (6x7)x(3x3)입니다. 구체적인 과정은 아래에서 살펴보도록 하겠습니다.
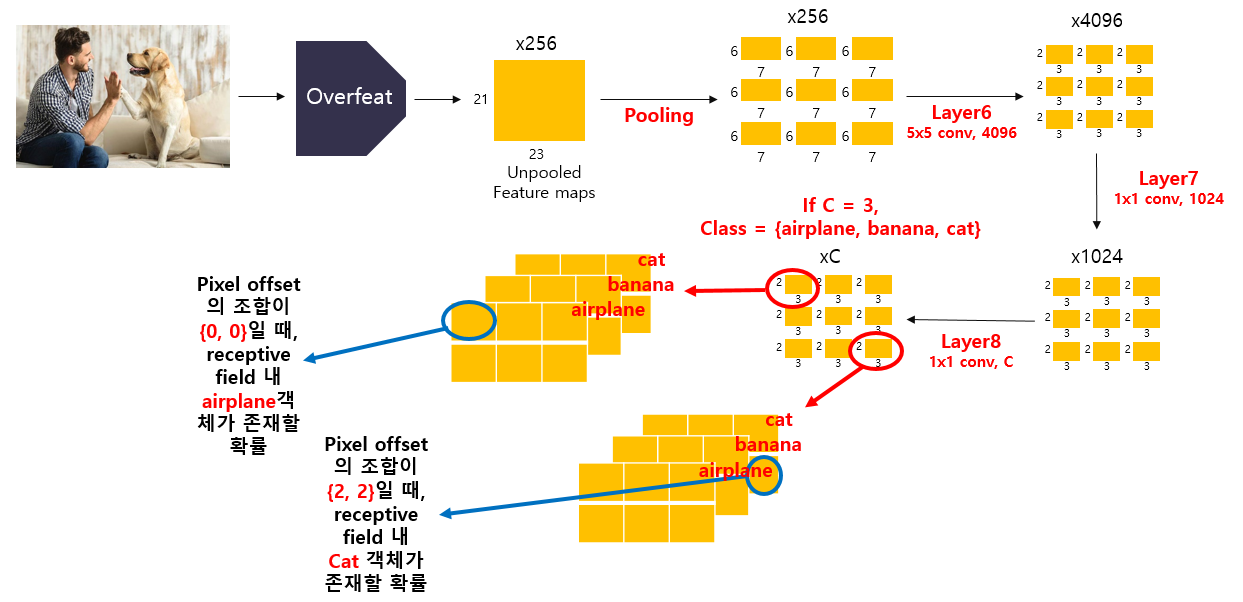
1) 하나의 이미지가 특정 비율로 주어졌을 때, CNN 모델에 입력하여 layer5에서 pooling을 진행하지 않고 feature map을 얻습니다.
2) pooling 되지 않은 feature map에 pixel offset {0, 1, 2}의 조합에 따라 3x3 max pooling(non-overlapping)을 적용합니다.
3) feature map은 이전에 학습시킨 Classifier(layer 6,7,8)를 거쳐 spatial output을 산출합니다.
4) spatial output은 3D output map(feature map width x height x C classes)로 reshape합니다.
위의 그림은 scale 2 이미지(281x317)가 입력되었을 때 Classifier가 동작하는 과정을 보여주고 있습니다(직접 그렸습니다!). 여기서 최종spatial output의 각 pixel이 가지는 의미를 직관적으로 이해하는 것이 중요하다고 생각합니다. 위의 그림을 참고하면 spatial output의 각 pixel 값이 pooling 시 어떤 pixel offset 조합인지(원본 이미지의 어떤 receptive field에 해당), 어떤 class를 예측하는지, 하는지를 파악하는 데 도움이 될 것 같습니다. Classifier는 이처럼 spatial output을 통해 원본 이미지의 특정 receptive field에 대한 confidence score와 class를 출력합니다.
3. Training Bounding box regressor
예측 box의 위치를 출력하는 Bounding box regressor는 Classifier와 학습 과정이 크게 다르지 않습니다. 다만 학습 시 Bounding box regressor는 6 scale의 이미지를 사용하며, 마지막 layer의 output이 4(x1, y1, x2, y2)xC(=class)가 되도록 조정합니다. 또한 ground truth box와 IoU가 0.5 미만인 예측 box는 학습에 포함시키지 않습니다.
1) Classification task를 위해 미리 학습시킨 Overfeat 모델을 layer5까지만 불러와 feature extractor로 사용하고 layer6(5x5 conv, 4096), layer7(1x1 conv, 4096x4096), layer8(1x1, 4096x4)를 추가합니다.
2) 이미지를 feature extractor(~layer5)에 입력하여 5x5 크기의 feature map을 256개를 출력합니다.
3) 5x5 크기의 feature map을 layer 6,7,8에 입력하여 1x1x4xC(=class) 크기의 feature map을 출력합니다.
4) loss function(L2 loss)을 통해 학습시킵니다.
4. Inference by Bounding box regressor
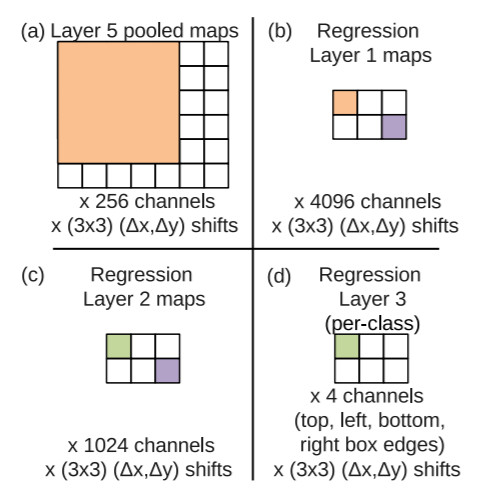
Bounding box regressor를 통한 localization 과정 역시 Classifier의 Inference 과정과 크게 다르지 않습니다. 각 spatial map의 pixel 값은 각 class별, bounding box의 x1, y1, x2, y2 좌표를 나타냅니다. 따라서 spatial output의 channel 수는 4 x C(=class)입니다. 위의 그림은 논문에 첨부된 그림으로, feature map이 각 layer를 거침에 따라 변화되는 크기를 잘 보여줍니다.
5. Greedy Merge Strategy

위와 같은 과정을 거치면 Overfeat은 detection 시, 6 scale에 대하여 굉장히 많은 예측 bounding box를 가지게 됩니다. 뿐만 아니라 논문의 저자가 정의한 pixel offset 조합에 따른 pooling으로 인해 예측 bounding box의 수가 9배나 증가합니다. 논문에서는 최적의 bounding box를 출력하기 위해 불필요한 box를 병합하는 Greedy Merge Strategy 알고리즘을 적용합니다. Greedy Merge Strategy 알고리즘은 다음과 같은 순서로 동작합니다.
1) $C_s(s=scale)$에 해당 scale의 spatial output에 대하여 각 pixel에서 가장 높은 confidence score를 가지는 class를 해당 location에 할당합니다.
2) $B_s(s=scale)$에 해당 scale의 spatial output에 bounding box 좌표를 할당합니다.
3) $B$에 모든 $B_s$를 할당합니다.
4) 결과가 산출되기 전까지 아래의 병합 과정을 반복합니다.
- $B$에서 $b_1, b_2$를 뽑아서 $matchScore$ 적용 후 가장 작은 $b_1, b_2$를 $b_1^*, b_2^*$에 할당
- 만약 $matchScore(b_1^*, b_2^*)$ > t 이면 멈춤
- 그렇지 않으면 B에 $boxMerge(b_1^*, b_2^*)$를 $b_1, b_2$ 대신에 넣음
$matchoScore$ : 두 bounding box의 중심 좌표 사이의 거리의 합과 IoU를 사용하여 측정
$boxMerge$ : bounding box 좌표의 평균 계산
위의 과정을 거쳐 병합된 bounding box 중에서 confidence score가 높은 box를 최종 예측으로 출력합니다. 논문의 저자가 제시한 방법은 False Positive sample에 보다 강건하다는 점에서 전통적인 Non maximum suppression보다 좋은 성능을 보인다고 합니다.
지금까지 Overfeat 모델의 학습 방법과 detection 과정을 살펴보았습니다. Overfeat 모델은 ILSVRC 2013 Challenge Classification, Localization, Detection task에서 각각 4위, 1위, 1위를 차지했습니다. 하지만 Selective search를 사용하여 후보 영역을 추출한 R-CNN에 비해 detection 성능면에서 부족한 면모를 보였습니다. 그럼에도 SSD, YOLO 등 후속 모델에 큰 영향을 끼쳤다는 점에서 의의가 있습니다.
모델의 설계 방식 자체가 R-CNN 모델과 차이가 있으며, 논문 자체가 친절하게 설명해주지 않아서 이해하고 정리하는데 정말 많은 시간이 걸렸던 것 같습니다😭. 심지어 python으로 구현된 코드도 없어, 이해하기가 더 까다로웠습니다. 그럼에도 앞으로 살펴볼 One stage detector 모델이 어떤 식으로 동작하는지 깊게 파볼 수 있는 좋은 기회였던 것 같습니다. 다음 포스팅에서는 Fast R-CNN 논문을 읽고 리뷰하도록 하겠습니다.

Reference
Overfeat 논문(Integrated Recognition, Localization and Detectionusing Convolutional Networks)



