
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- Region proposal Network
- Darknet
- BiFPN
- YOLO
- Anchor box
- multi task loss
- detr
- Bounding box regressor
- herbwood
- fine tune AlexNet
- Detection Transformer
- Map
- AP
- hard negative mining
- Fast R-CNN
- R-CNN
- Object Detection
- Non maximum suppression
- IOU
- Multi-task loss
- Average Precision
- Hungarian algorithm
- Faster R-CNN
- mean Average Precision
- pytorch
- RPN
- Linear SVM
- RoI pooling
- Object Detection metric
- object queries
- Today
- Total
약초의 숲으로 놀러오세요
Python으로 구현한 mAP(mean Average Precision) 본문
이번 포스팅에서는 Object Detection 모델의 성능 평가 지표인 mAP(mean Average Precision)을 python으로 구현하는 과정을 살펴보도록 하겠습니다. 구현 과정을 살펴보면 Kaggle과 같은 경진대회 참여시, 모델의 평가 방법에 대해 구체적으로 파악할 수 있어 앞으로 꼭 도움이 될 것이라고 생각합니다. 구현 코드는 rafaelpadilla님의 github repository를 많은 부분 참고했으며, 코드는 제 github repository에 올려두었습니다. Object Detection의 정의와 mAP에 대한 설명은 Object Detection의 정의와 Metric mAP(mean Average Precision) 포스팅을 참고하시기 바랍니다.

저는 구현된 코드를 실험해보기 위해 아프리카 야생 동물 4종(코끼리, 아프리카들소, 코뿔소, 얼룩말)의 이미지와 annotation이 포함된 African Wildlife Dataset을 활용했습니다. 데이터셋은 이미지와 이미지 파일과 같은 이름의 텍스트 파일에 annotation 정보가 포함되어 있습니다(0001.jpg 이미지에 대한 annotation 정보는 0001.txt). detected box와 groundtruth box에 대한 annotation은 label 디렉터리 내 각각 다른 위치에 저장했습니다. annotation 정보는 아래와 같은 형식으로 구성되어 있습니다.
0 1 0.213281 0.506081 0.204688 0.290541
0 1 0.723437 0.620270 0.304688 0.313514
3 1 0.059766 0.631081 0.107031 0.308108
3 1 0.156641 0.662162 0.139844 0.227027
3 1 0.281250 0.672973 0.090625 0.240541
위의 정보는 하나의 이미지 내에서 탐지된 객체에 대한 annotation 정보를 나타냅니다. 위의 예시의 경우 5개의 객체가 있음을 나타내고 있습니다. 셈입니다. 각 줄은 순서대로 class index, confidence score, centerX, centerY, width, heigth를 나타냅니다. class index는 객체의 class에 대한 인덱스값으로 각 인덱스별 class는 다음과 같습니다; {"0.0" : "buffalo", "1.0" : "elephant", "2.0" : "rhino", "3.0" : "zebra"}. confidence score는 ground truth box인 경우 1로 지정했습니다.
다운받은 데이터셋의 bounding box의 좌표가 YOLO 형식으로 저장되어 있다는 것을 뒤늦게 알았습니다😂 PASCAL VOC는 bounding box의 좌표를 좌상단, 우하단 형식(x1, y1, x2, y2)으로, 절대값으로 나타냅니다. 반면 YOLO 형식은 bounding box의 중심값 x,y 좌표와 box의 넓이와 높이(centerX, centerY, width, height)를 상대값으로 나타냅니다. 상대값을 좌표로 사용하게 되면 실제 box의 위치를 나타내는 좌표가 아니라 이미지 크기에 비례한 box의 위치를 비율로 나타냅니다. 예를 들어 너비가 100인 이미지에서 box의 x좌표가 80인 경우 상대값으로 나타내면 0.8이 됩니다.
1) YOLO 형식 좌표를 VOC 형식 좌표로 변환하기
먼저 계산의 편의를 위해 YOLO 형식 좌표를 VOC 형식 좌표로 변환하도록 하겠습니다.
def convertToAbsoluteValues(size, box):
xIn = round(((2 * float(box[0]) - float(box[2])) * size[0] / 2))
yIn = round(((2 * float(box[1]) - float(box[3])) * size[1] / 2))
xEnd = xIn + round(float(box[2]) * size[0])
yEnd = yIn + round(float(box[3]) * size[1])
if xIn < 0:
xIn = 0
if yIn < 0:
yIn = 0
if xEnd >= size[0]:
xEnd = size[0] - 1
if yEnd >= size[1]:
yEnd = size[1] - 1
return (xIn, yIn, xEnd, yEnd)

먼저 box의 좌상단, 우하단 상대값 좌표부터 구해줍니다. 어떤 식으로 변환해야할지 도저히 감이 잡히지 않아서 위와 같이 직접 그림을 그려봤습니다. 검정색 box는 전체 이미지를, 빨간색 box는 bounding box입니다. centerX, centerY가 bounding box의 중심에 위치했다는 것을 이용하여 좌상단 좌표$(x - 1/2 * w, y - 1/2 * h)$를 구할 수 있으며, 좌상단 좌표를 이용하면 우하단 좌표는 쉽게 구할 수 있습니다. 여기서 절대값으로 좌표를 만들어주기 위해 각 좌표값에 너비와 높이를 곱해줍니다.
위의 코드에서 convertToAbsoluteValues 함수는 이미지의 크기와 bounding box의 상대값 좌표를 인자로 받습니다. box 변수는 (centerX, centerY, width, height)입니다. 코드는 계산의 편의를 위해 2를 곱해 $(2 * x - w, 2 * y - h)$로 만들어준 뒤 다시 2로 나눠주는 식으로 구현했습니다. 마지막으로 좌표값이 음수가 되는 것을 방지하기 위해 조건문을 추가했습니다.
2) Bounding box 정보 추가하기
다음으로 bounding box에 대한 정보를 저장하는 과정을 살펴보도록 하겠습니다.
def boundingBoxes(labelPath, imagePath):
detections, groundtruths, classes = [], [], []
for boxtype in os.listdir(labelPath):
boxtypeDir = os.path.join(labelPath,boxtype)
for labelfile in os.listdir(boxtypeDir):
filename = os.path.splitext(labelfile)[0]
with open(os.path.join(boxtypeDir, labelfile)) as f:
labelinfos = f.readlines()
imgfilepath = os.path.join(imagePath, filename + ".jpg")
img = cv.imread(imgfilepath)
h, w, _ = img.shape
for labelinfo in labelinfos:
label, conf, rx1, ry1, rx2, ry2 = map(float, labelinfo.strip().split())
x1, y1, x2, y2 = convertToAbsoluteValues((w, h), (rx1, ry1, rx2, ry2))
boxinfo = [filename, label, conf, (x1, y1, x2, y2)]
if label not in classes:
classes.append(label)
if boxtype == "detection":
detections.append(boxinfo)
else:
groundtruths.append(boxinfo)
classes = sorted(classes)
return detections, groundtruths, classes

위의 코드는 labelPath에 있는 각 디렉터리로부터 annotation 정보가 담긴 텍스트 파일을 읽어 모든 bounding box에 대한 정보를 저장하는 과정을 담고 있습니다. 포함하는 정보는 box가 위치한 이미지 파일명, class 인덱스, confidence score, 절대값으로 변환된 좌표입니다. detections 리스트에는 모델이 예측한 detected box에 대한 정보를, groundtruths 리스트에는 실제 객체의 위치인 ground truth box에 대한 정보를 저장합니다. 마지막으로 객체 class에 대한 정보를 classes 리스트에 저장했습니다. 위의 bounding box 정보를 활용하여 시각화한 결과는 위와 같습니다. 빨간색 box는 detected box를, 초록색 box는 ground truth box입니다.
3) IoU(Intersection over Union) 구하기
다음으로 IoU(Intersection over Union)을 계산하는 함수를 구현해보도록 하겠습니다. 두 box가 겹치는 영역을 계산하는 부분 외에는 크게 어렵지 않습니다.
def getArea(box):
return (box[2] - box[0] + 1) * (box[3] - box[1] + 1)
def getUnionAreas(boxA, boxB, interArea=None):
area_A = getArea(boxA)
area_B = getArea(boxB)
if interArea is None:
interArea = getIntersectionArea(boxA, boxB)
return float(area_A + area_B - interArea)
def getIntersectionArea(boxA, boxB):
xA = max(boxA[0], boxB[0])
yA = max(boxA[1], boxB[1])
xB = min(boxA[2], boxB[2])
yB = min(boxA[3], boxB[3])
# intersection area
return (xB - xA + 1) * (yB - yA + 1)
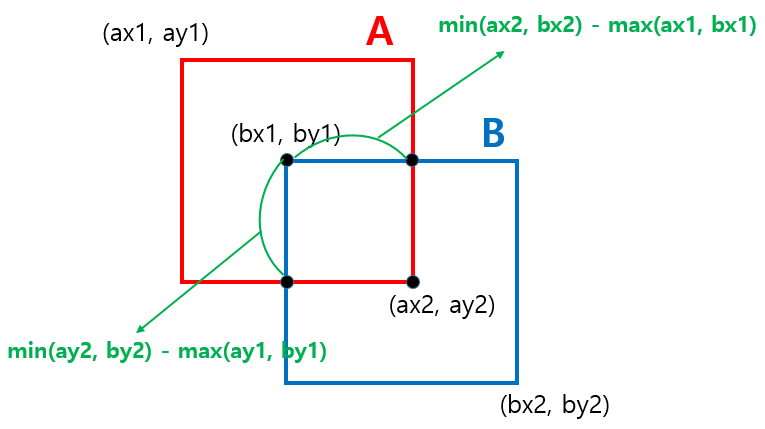
- getArea : box의 절대값 좌표를 인자로 받아 box의 넓이를 반환합니다.
- getUnionArea : 두 box의 절대값 좌표를 인자로 받아 두 box의 넓이에서 box가 겹치는 영역을 제외하여 두 box의 합집합 영역의 크기를 반환합니다.
- getIntersectionArea : 두 box의 절대값 좌표를 인자로 받아 두 box가 겹치는 영역을 반환합니다. 이 부분 역시 명확하게 이해가 되지 않아 다시🤣 그림을 그려봤습니다. 위의 그림에서 볼 수 있듯이 box A와 box B의 좌상단 우하단 좌표를 비교하고 이를 활용하여 두 box가 겹치는 영역의 넓이를 구할 수 있습니다.
def boxesIntersect(boxA, boxB):
if boxA[0] > boxB[2]:
return False # boxA is right of boxB
if boxB[0] > boxA[2]:
return False # boxA is left of boxB
if boxA[3] < boxB[1]:
return False # boxA is above boxB
if boxA[1] > boxB[3]:
return False # boxA is below boxB
return True
def iou(boxA, boxB):
# if boxes dont intersect
if boxesIntersect(boxA, boxB) is False:
return 0
interArea = getIntersectionArea(boxA, boxB)
union = getUnionAreas(boxA, boxB, interArea=interArea)
# intersection over union
result = interArea / union
assert result >= 0
return result
- boxesIntersect : 두 box의 절대값 좌표를 인자로 받아 좌표값을 비교하여 두 box가 겹치는지 여부를 boolean 타입으로 반환합니다.
- iou : 두 box의 절대값 좌표를 인자로 받아 IoU를 계산하여 반환합니다.
4) AP(Average Precision) 구하기
다음으로 class별로 AP(Average Precision)를 구하는 코드를 살펴보겠습니다.
def AP(detections, groundtruths, classes, IOUThreshold = 0.3, method = 'AP'):
# 클래스별 AP, Precision, Recall 등 관련 정보를 저장할 리스트
result = []
# 클래스별로 접근
for c in classes:
# 특정 class에 해당하는 box를 box타입(detected, ground truth)에 따라 분류
dects = [d for d in detections if d[1] == c]
gts = [g for g in groundtruths if g[1] == c]
# 전체 ground truth box의 수
# Recall 값의 분모
npos = len(gts)
# confidence score에 따라 내림차순 정렬
dects = sorted(dects, key = lambda conf : conf[2], reverse=True)
TP = np.zeros(len(dects))
FP = np.zeros(len(dects))
# 각 이미지별 ground truth box의 수
# {99 : 2, 380 : 4, ....}
det = Counter(cc[0] for cc in gts)
# {99 : [0, 0], 380 : [0, 0, 0, 0], ...}
for key, val in det.items():
det[key] = np.zeros(val)
(...)
각 클래스별로 AP 값을 구하고, 관련 정보를 result 리스트에 저장할 것입니다. 먼저 반복문을 통해 특정 class에 해당하는 bounding box를 box타입(detetcted, ground truth)에 따라 구분하여 서로 다른 리스트에 저장해줍니다. 이후 detected box가 저장된 리스트를 confidence score에 따라 내림차순으로 정렬합니다. 이는 confidence score의 변화에 따라 달라지는 Precision, Recall을 확인하기 위함입니다.
TP, FP 변수는 confidence score에 따른 bouding box의 결과(TP, FP 여부)를 저장하는 배열입니다. 마지막으로 det 변수는 각 이미지별로 존재하는 ground truth box의 수를 영배열로 저장했습니다. 이를 굳이 영배열로 저장한 이유는 각 ground truth box에 매칭된 detected box가 있는지 여부를 파악하는 flag 기능을 구현하기 위함입니다. 만약 이미 매칭된 detected box가 있는 경우 1로 값을 바꿔주게 됩니다.
def AP(detections, groundtruths, classes, IOUThreshold = 0.3, method = 'AP'):
(...)
# 전체 detected box
for d in range(len(dects)):
# ground truth box 중에서 detected box와 같은 이미지 파일에 존재하는 box
# dects[d][0] : 이미지 파일명
gt = [gt for gt in gts if gt[0] == dects[d][0]]
iouMax = 0
# 하나의 detected box에 대하여 같은 이미지에 존재하는 모든 ground truth 값을 비교
# 가장 큰 IoU 값을 가지는 하나의 ground truth box에 매칭
for j in range(len(gt)):
iou1 = iou(dects[d][3], gt[j][3])
if iou1 > iouMax:
iouMax = iou1
jmax = j
# IoU 임계값 이상 and ground truth box가 매칭되지 않음 => TP
# IoU 임계값 미만 or ground truth box가 다른 detected box에 이미 매칭됨 => FP
if iouMax >= IOUThreshold:
if det[dects[d][0]][jmax] == 0:
TP[d] = 1
det[dects[d][0]][jmax] = 1
else:
FP[d] = 1
else:
FP[d] = 1
# Precision, Recall 값을 구하기 위한 누적 TP, FP
acc_FP = np.cumsum(FP)
acc_TP = np.cumsum(TP)
rec = acc_TP / npos
prec = np.divide(acc_TP, (acc_FP + acc_TP))
(...)
다음으로 각 detected box별로 ground truth box과 매칭하여 IoU 값을 구하는 과정을 살펴보겠습니다. 먼저 ground truth box 중 detected box와 같은 이미지 파일 내에 있는 box를 골라내 gt 변수에 저장합니다. IoU값은 같은 이미지 내 있는 box를 통해 구할 수 있기 때문입니다.
이후 하나의 detected box에 대하여 같은 이미지 파일 내에 있는 모든 ground truth box와의 IoU 값을 구합니다. 그 중 가장 큰 IoU 값을 가지는 ground truth box를 파악하고 해당 box와의 IoU 값이 IoU 임계값 이상이고, 이미 매칭된 detected box가 없는 경우 TP를 1로, 그렇지 않은 경우는 FP를 1로 바꿔줍니다. 매칭 여부는 위에서 언급한 flag 기능을 수행하는 det 변수를 통해 파악 가능합니다. 이후 Precision, Recall 값을 구하기 위해 각 구간별로 누적 TP, FP를 구해 최종적으로 Precision, Recall 값을 구합니다.

가장 큰 IoU 값을 가진 ground truth box를 파악해야 하는 이유는 위의 그림에서 볼 수 있듯이 하나의 detected box가 다수의 ground truth box에 걸쳐 있는 경우가 생기기 때문입니다. 이같은 경우 detected box는 IoU값이 가장 큰 ground truth box를 탐지했다고 간주합니다. 위의 그림에서 detected box는 IoU 값이 더 큰 ground truth box A와 매칭됩니다. 저는 이 부분이 헷갈려서 다시 한 번 그림으로 그려봤습니다🤣. 공부하면서 PPT 실력이 느는 기분입니다.
def AP(detections, groundtruths, classes, IOUThreshold = 0.3, method = 'AP'):
(...)
if method == "AP":
[ap, mpre, mrec, ii] = calculateAveragePrecision(rec, prec)
else:
[ap, mpre, mrec, _] = ElevenPointInterpolatedAP(rec, prec)
r = {
'class' : c,
'precision' : prec,
'recall' : rec,
'AP' : ap,
'interpolated precision' : mpre,
'interpolated recall' : mrec,
'total positives' : npos,
'total TP' : np.sum(TP),
'total FP' : np.sum(FP)
}
result.append(r)
return result
마지막으로 PR 곡선의 면적을 11점 보간법(11-point interpolation)을 통해 구해줍니다. 면적을 구하는 코드는 바로 아래에서 설명하도록 하겠습니다. 이후 r 변수에 class에 대한 Precision, Recall, AP 등과 같은 추정 결과를 저장합니다. 모든 class에 대하여 위의 과정을 반복하여 result 리스트에 저장하면 모든 class에 대한 AP 값을 구할 수 있습니다.
def ElevenPointInterpolatedAP(rec, prec):
mrec = [e for e in rec]
mpre = [e for e in prec]
# recallValues = [1.0, 0.9, ..., 0.0]
recallValues = np.linspace(0, 1, 11)
recallValues = list(recallValues[::-1])
rhoInterp, recallValid = [], []
for r in recallValues:
# r : recall값의 구간
# argGreaterRecalls : r보다 큰 값의 index
argGreaterRecalls = np.argwhere(mrec[:] >= r)
pmax = 0
print(r, argGreaterRecalls)
# precision 값 중에서 r 구간의 recall 값에 해당하는 최댓값
if argGreaterRecalls.size != 0:
pmax = max(mpre[argGreaterRecalls.min():])
recallValid.append(r)
rhoInterp.append(pmax)
ap = sum(rhoInterp) / 11
return [ap, rhoInterp, recallValues, None]
11점 보간법(11-point interpolation)에 따라 Recall의 구간별로 Precision의 구합니다. 먼저 recallValues를 통해 0.1 간격으로 Recall 값의 구간을 지정해줍니다. 그리고 각 구간별로 Recall 값을 구하고(없을 경우 0), 구간에 맞는 Precision 값을 구하고 rhoInterp 리스트에 추가해줍니다. 그리고 rhoInterp에 저장된 값들의 평균을 구해 최종적으로 AP 값을 산출합니다.
4) mAP(mean Average Precision) 구하기
마지막으로 모든 class의 AP 값의 평균인 mAP(mean Average Precision)를 구하도록 하겠습니다.
def mAP(result):
ap = 0
for r in result:
ap += r['AP']
mAP = ap / len(result)
return mAP
앞서 class별 모든 AP 값이 저장된 result 변수를 인자로 받아 모든 AP값을 전체 class의 수(=result 리스트의 길이)로 나눠주면 됩니다.
지금까지 Object Detection에서 주로 사용되는 성능 평가 지표인 mAP를 python으로 구현하는 과정을 살펴봤습니다. 코드를 살펴보면서 이론으로 제대로 알고 있었다고 생각했지만 잘못 이해하거나 놓쳤던 부분이 있었다는 점을 깨달았습니다. detected box는 하나의 ground truth box에 매칭된다는 점은 생각해보면 당연하지만(box당 하나의 객체만의 예측하기에) 코드를 살펴보면서 알게 되었습니다. 그리고 알고리즘 공부의 필요성을 느꼈습니다😭. IoU, AP를 구하는 과정이 상당히 복잡했고, 자료 구조의 활용을 자유롭게 할 수 있다면 코드 구현 과정이 보다 용이할 것 같다는 생각이 들었습니다. 마지막으로 코드로 구현하기 위해 직접 이미지의 예시 bounding box를 만드는 과정에서 이미지 레이블링 툴인 labelImg를 사용해보고, YOLO 형식에 대해 배울 수 있었습니다. 저는 jupyter notebook으로 필수적인 기능만 구현했지만 모듈로 기능을 구분하고 선택지가 더 많은 rafaelpadilla님의 github repository를 참고해보시면 좋을 것 같습니다.
Reference
Object Detection의 정의와 Metric mAP(mean Average Precision)
Python으로 구현한 mAP(mean Average Precision)
rafaelpadilla님의 github repository(metrics for object detection)
'Computer Vision > Code Review' 카테고리의 다른 글
| Pytorch로 구현한 YOLO v1 모델 (0) | 2020.12.31 |
|---|---|
| Pytorch로 구현한 Faster R-CNN 모델 (9) | 2020.12.23 |
| Pytorch로 구현한 Fast R-CNN 모델 (2) | 2020.12.10 |
| Pytorch로 구현한 R-CNN 모델 (9) | 2020.11.28 |



