
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- Linear SVM
- Detection Transformer
- Bounding box regressor
- Average Precision
- mean Average Precision
- detr
- Hungarian algorithm
- fine tune AlexNet
- YOLO
- RPN
- BiFPN
- Anchor box
- hard negative mining
- R-CNN
- Multi-task loss
- RoI pooling
- multi task loss
- Darknet
- IOU
- pytorch
- Object Detection
- herbwood
- AP
- Fast R-CNN
- object queries
- Faster R-CNN
- Object Detection metric
- Region proposal Network
- Map
- Non maximum suppression
- Today
- Total
약초의 숲으로 놀러오세요
FPN 논문(Feature Pyramid Networks for Object Detection) 리뷰 본문
FPN 논문(Feature Pyramid Networks for Object Detection) 리뷰
herbwood 2021. 1. 27. 18:24이번 포스팅에서는 FPN 논문(Feature Pyramid Networks for Object Detection)을 리뷰해보도록 하겠습니다. 이미지 내 존재하는 다양한 크기의 객체를 인식하는 것은 Object dection task의 핵심적인 문제입니다. 모델이 크기에 상관없이 객체를 detect할 수 있도록 다양한 방법을 사용해왔습니다. 하지만 기존의 방식을 사용하면 모델의 추론 속도가 너무 느려지며, 메모리를 지나치게 많이 사용한다는 문제가 있습니다. 본 논문에서는 FPN(Feature Pyramid Network)을 통해 컴퓨팅 자원을 적게 차지하면서 다양한 크기의 객체를 인식하는 방법을 제시합니다. 기존 방식의 문제점과 더불어 FPN의 핵심 아이디어, 그리고 Faster R-CNN과 결합된 FPN의 학습 과정과 성능에 대해 살펴보도록 하겠습니다.
Preview
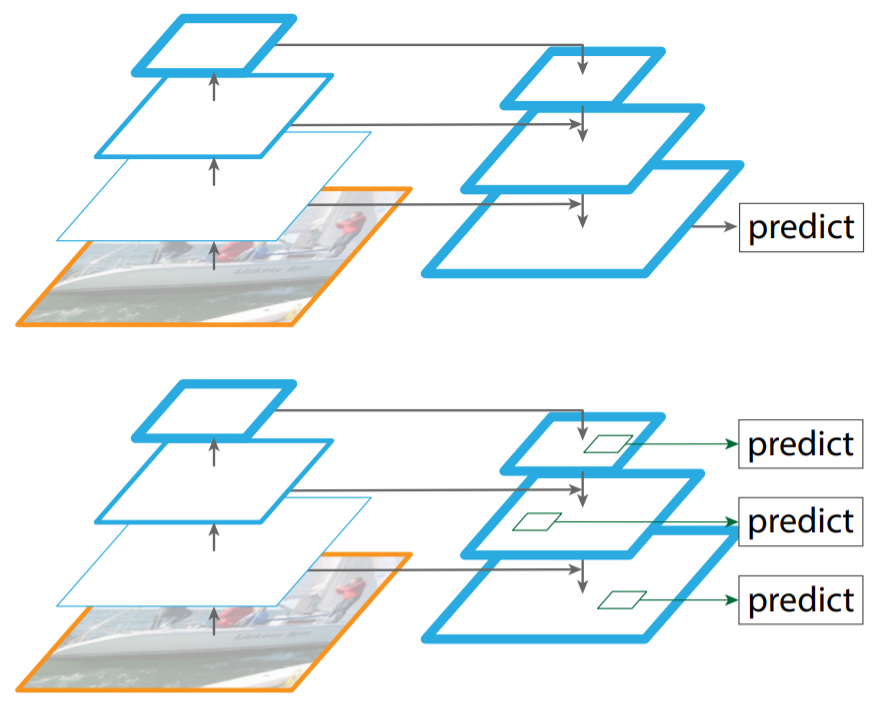
원본 이미지를 convolutional network에 입력하여 forward pass를 수행하고, 각 stage마다 서로 다른 scale을 가지는 4개의 feature map을 추출합니다. 이 과정을 Bottom-up pathway라고 합니다. 이후 Top-down pathway를 통해 각 feature map에 1x1 conv 연산을 적용하여 모두 256 channel을 가지도록 조정하고 upsampling을 수행합니다. 마지막으로 Lateral connections 과정을 통해 pyramid level 바로 아래 있는 feature map과 element-wise addition 연산을 수행합니다. 이를 통해 얻은 4개의 서로 다른 feature map에 3x3 conv 연산을 적용합니다.
Main Ideas
Pyramid란?

해당 논문에서는 "Pyramid"라는 단어가 자주 등장하는데, 이는 convolutional network에서 얻을 수 있는 서로 다른 해상도의 feature map을 쌓아올린 형태라고 생각하시면 됩니다. 그리고 level은 피라미드의 각 층에 해당하는 feature map입니다. 여기서 feature map의 해상도와 각각 보유하고 있는 representation의 관계에 대해 짚고 넘어가도록 하겠습니다.

convolutional network에서 더 얕은, 즉 입력층에 보다 가까울수록 feature map은 높은 해상도(high resolution)을 가지지며, 가장자리, 곡선 등과 같은 저수준 특징(low-level feature)을 보유하고 있습니다. 반대로 더 깊은 layer에서 얻을 수 있는 feature map은 낮은 해상도(low resolution)을 가지며, 질감과 물체의 일부분 등 class를 추론할 수 있는 고수준 특징(high-level feature)을 가지고 있습니다.
Object detection 모델은 피라미드의 각 level의 feature map을 일부 혹은 전부 사용하여 예측을 수행합니다. 이 부분에 대해 직관적으로 이해하고 넘어가면 FPN을 이해하기 한결 수월할 것 같습니다.
기존의 방식
다양한 크기의 객체를 detect하도록 모델을 학습시키기 위해 다양한 시도가 있었습니다. 기존의 방식과 각각의 문제점을 살펴보도록 하겠습니다.

(a) Featurized image pyramid
입력 이미지의 크기를 resize하여 다양한 scale의 이미지를 네트워크에 입력하는 방법입니다. Overfeat 모델 학습 시 해당 방법을 사용했습니다. 다양한 크기의 객체를 포착하는데 좋은 결과를 보여줍니다. 하지만 이미지 한 장을 독립적으로 모델에 입력하여 feature map을 생성하기 때문에 추론 속도가 매우 느리며, 메모리를 지나치게 많이 사용한다는 문제가 있습니다.
(b) Single feature map
단일 scale의 입력 이미지를 네트워크에 입력하여 단일 scale의 feature map을 통해 object detection을 수행하는 방법입니다. YOLO v1 모델 학습 시 해당 방법을 사용했습니다. 학습 및 추론 속도가 매우 빠르다는 장점이 있지만 성능이 떨어진다는 단점이 있습니다.
(c) Pyramidal feature hierarchy
네트워크에서 미리 지정한 conv layer마다 feature map을 추출하여 detect하는 방법입니다. SSD 모델 학습 시 해당 방법을 사용했습니다. multi-scale feature map을 사용하기 때문에 성능이 높다는 장점이 있지만 feature map 간 해상도 차이로 인해 학습하는 representation에서 차이인 semantic gap이 발생한다는 문제가 있습니다. 모델이 얕은 layer에서 추출한 feature map에서 저수준 특징(low-level feature)까지 학습하면 representational capacity를 손상시켜 객체 인식률이 낮아진다고 합니다.
SSD는 위에서 언급한 문제를 해결하기 위해 low-level feature를 사용하지 않고, 전체 convolutional network 중간 지점부터 feature map을 추출합니다. 하지만 FPN 논문의 저자는 높은 해상도의 feature map은 작은 객체를 detect할 때 유용하기 때문에 이를 사용하지 않는 것은 적절하지 않다고 지적합니다.
Feature Pyramid Network
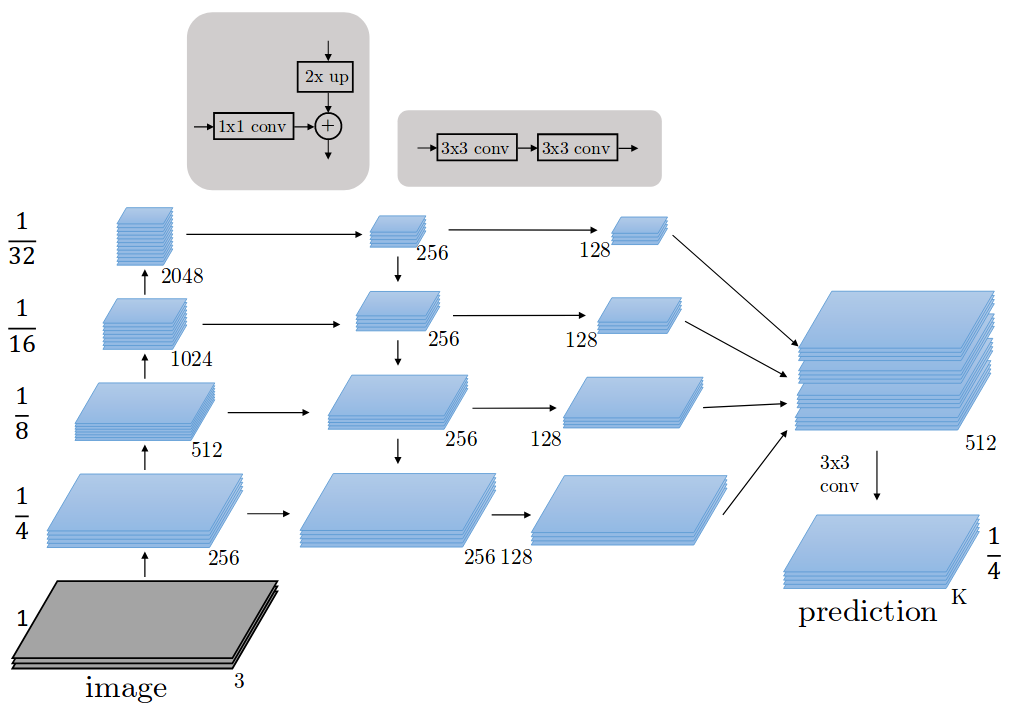
Feature Pyramid Network는 임의의 크기의 single-scale 이미지를 convolutional network에 입력하여 다양한 scale의 feature map을 출력하는 네트워크입니다. 논문에서는 ResNet을 사용합니다. FPN는 완전 새롭게 설계된 모델이 아니라 기존 convolutional network에서 지정한 layer별로 feature map을 추출하여 수정하는 네트워크라고 이해하시면 됩니다. FPN이 feature map을 추출하여 피라미드를 건축하는 과정은 bottom-up pathway, top-down pathway, lateral connections에 따라 진행됩니다.
Bottom-up pathway

Bottom-up pathway 과정은 이미지를 convolutional network에 입력하여 forward pass하여 2배씩 작아지는 feature map을 추출하는 과정입니다. 이 때 각 stage의 마지막 layer의 output feature map을 추출합니다. 네트워크에는 같은 크기의 feature map을 출력하는 layer가 많지만 논문에서는 이러한 layer를 모두 같은 stage에 속해있다고 정의합니다. 각 stage에서 별로 마지막 layer를 pyramid level로 지정하는 이유는 더 깊은 layer일수록 더 강력한 feature를 보유하고 있기 때문입니다.
ResNet의 경우 각 stage의 마지막 residual block의 output feature map을 활용하여 feature pyramid를 구성하며 각 output을 {c2, c3, c4, c5}라고 지정합니다. 이는 conv2, conv3, conv4, conv5의 output feature map임을 의미하며, 각각 {4, 8, 16, 32} stride를 가지고 있습니다. 여기서 {c2, c3, c4, c5}은 각각 원본 이미지의 1/4, 1/8, 1/16, 1/32 크기를 가진 feature map입니다. conv1의 output feature map은 너무 많은 메모리를 차지하기 때문에 피라미드에서 제외되었다고 합니다.
Top-down pathway and Lateral connections

Top-down Pathway는 각 pyramid level에 있는 feature map을 2배로 upsampling하고 channel 수를 동일하게 맞춰주는 과정입니다. 각 pyramid level의 feature map을 2배로 upsampling해주면 바로 아래 level의 feature map와 크기가 같아집니다. 가령 c2는 c3와 크기가 같아집니다. 이 때 nearest neighbor upsampling 방식을 사용합니다. 이후 모든 pyramid level의 feature map에 1x1 conv 연산을 적용하여 channel을 256으로 맞춥니다.

그 다음 upsample된 feature map과 바로 아래 level의 feature map과 element-wise addition 연산을 하는 Lateral connections 과정을 수행합니다. 이후각각의 feature map에 3x3 conv 연산을 적용하여 얻은 feature map을 각각 {p2, p3, p4, p5}입니다. 이는 각각 {c2, c3, c4, c5} feature map의 크기와 같습니다. 가장 높은 level에 있는 feature map c2의 경우 1x1 conv 연산 후 그대로 출력하여 p2를 얻습니다.

위의 과정을 통해 FPN은 single-scale 이미지를 입력하여 4개의 서로 다른 scale을 가진 feature map을 얻습니다. 단일 크기의 이미지를 모델에 입력하기 때문에 기존 방식 (a) 방식에 비해 빠르고 메모리를 덜 차지합니다. 또한 multi-scale feature map을 출력하기 때문에 (b) 방식보다 더 높은 detection 성능을 보여줍니다.
Detection task 시 고해상도 feature map은 low-level feature를 가지지만 객체의 위치에 대한 정보를 상대적으로 정확하게 보존하고 있습니다. 이는 저해상도 feature map에 비해 downsample된 수가 적기 때문입니다. 이러한 고해상도 feature map의 특징을 element-wise addition을 통해 저해상도 feature map에 전달하기 때문에 (c)에 비해 작은 객체를 더 잘 detect합니다.
Training ResNet + Faster R-CNN with FPN
논문에서는 ResNet을 backbone network로 사용하는 Faster R-CNN에 FPN을 적용하여 학습시키는 과정을 설명합니다. Faster R-CNN에 대한 자세한 설명은 Faster R-CNN 논문 리뷰 포스팅을 참고하시기 바랍니다.

1) Build Feature Pyramid by FPN
먼저 ResNet 기반의 FPN에 이미지를 입력한 후 Bottom-up pathway을 거쳐 원본 이미지의 1/4, 1/8, 1/16, 1/32 크기에 해당하는 feature map {c2, c3, c4, c5}을 출력합니다. 이후 Top-down pathway 과정을 통해 1x1 conv 연산을 적용하여 모든 feature map의 channel 수를 256으로 맞춰주고 크기를 2배로 upsampling해줍니다. 마지막으로 Lateral connections을 통해 각 feature map을 바로 아래 pyramid level에 존재하는 feature map과 element-wise addtion 연산을 수행합니다. 이후 3x3 conv 연산을 수행하여 {p2, p3, p4, p5} feature map을 출력합니다.
앞선 과정을 통해 얻은 feature pyramid {p2, p3, p4, p5}는 RPN와 RoI pooling 시 사용됩니다.
- Input : single-scale image
- Process : build feature pyramid
- Output : multi-scale feature map {p2, p3, p4, p5}
2) Class score and Bounding box by RPN

앞선 과정에서 얻은 feature map {p2, p3, p4, p5}를 RPN(Region Proposal Network)에 입력합니다. 이 때 각 feature map을 위의 그림과 같이 개별적으로 RPN에 입력하여 각각의 class score과 bounding box regressor를 출력합니다. 이후 Non maximum suppression 알고리즘을 적용하여 class score가 높은 상위 1000개의 region proposal만을 출력합니다.
- Input : multi-scale feature map {p2, p3, p4, p5}
- Prcoess : region proposal and Non maximum suppression
- Output : 1000 region proposals
3) Max pooling by RoI pooling
1)번 과정에서 얻은 multi-scale feature map {p2, p3, p4, p5}와 2)번 과정을 통해 얻은 1000개의 region proposals를 사용하여 RoI pooling을 수행합니다. Fast R-CNN은 single-scale feature map만을 사용한 반면, FPN을 적용한 Faster R-CNN은 multi-scale feature map을 사용하기 때문 region proposals를 어떤 scale의 feature map과 매칭시킬지를 결정해야합니다.
$$k = [k_0 + log_{2}(\sqrt{wh}/224)]$$
논문에서는 위와 같은 공식에 따라 region proposal을 $k$번째 feature map과 매칭합니다. w, h는 RoI(=region proposal)의 width, height에 해당하며, $k$는 pyramid level의 index, $k_0$은 target level을 의미합니다. 논문에서는 $k0=4$로 지정했습니다. 직관적으로 봤을 때 RoI의 scale이 작아질수록 낮은 pyramid level, 즉 해상도가 높은 feature map에 할당하고 있음을 알 수 있습니다.
위와 같은 공식을 사용하여 region proposal과 index가 $k$인 feature map을 통해 RoI pooling을 수행합니다. 이를 통해 고정된 크기의 feature map을 얻을 수 있습니다.
- Input : multi-scale feature map {p2, p3, p4, p5} and 1000 region proposals
- Process : RoI pooling
- Output : fixed sized feature maps
4) Train Faster R-CNN
RoI pooling을 통해 얻은 고정된 크기의 feature map을 Fast R-CNN에 입력한 후 전체 네트워크를 multi-task loss function을 통해 학습시킵니다. 자세한 내용은 Fast R-CNN 논문 리뷰 포스팅을 참고하시기 바랍니다.
Detection
실제 inference 시에는 Fast R-CNN의 마지막 예측에 Non maximum suppression을 적용하여 최적의 예측 결과만을 출력합니다.
ResNet을 backbone network로 사용한 Faster R-CNN에 FPN을 결합시켰을 때, FPN을 사용하지 않았을 때보다 AP 값이 8% 이상 향상되었습니다. 이외에도 FPN은 end-to-end로 학습이 가능하며, 학습 및 테스트 시간이 일정하여 메모리 사용량이 적다는 장점을 보였습니다.
이번 논문을 통해 convolutional network의 feature map의 특징을 다시 한 번 짚고 넘어갈 수 있어 좋았습니다. 네트워크층이 얕은 layer의 feature map은 low-level이지만 localization에 유리한 feature를 보유하고 있는 반면, 깊은 layer의 feature map은 localization에 대한 정보는 적지만 class를 추론할 수 있는 high-level feature를 가지고 있습니다. 논문에서는 이러한 feature map에 대한 특성을 파악하여 두 종류의 feature map의 장점을 모두 활용할 수 있는 좋은 해결책을 제시한 것 같습니다. 다음 포스팅에서는 RetinaNet 논문을 읽고 리뷰해보도록 하겠습니다.

Reference
FPN 논문(Feature Pyramid Networks for Object Detection)
Visualization of neural network
'Computer Vision > Object Detection' 카테고리의 다른 글
| Mask R-CNN 논문(Mask R-CNN) 리뷰 (26) | 2021.02.14 |
|---|---|
| RetinaNet 논문(Focal Loss for Dense Object Detection) 리뷰 (5) | 2021.02.11 |
| YOLO v2 논문(YOLO9000:Better, Faster, Stronger) 리뷰 (2) | 2021.01.15 |
| R-FCN 논문(R-FCN: Object Detection via Region-based Fully Convolutional Networks) 리뷰 (0) | 2021.01.04 |
| SSD 논문(SSD: Single Shot MultiBox Detector) 리뷰 (10) | 2021.01.01 |



