
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- fine tune AlexNet
- R-CNN
- pytorch
- Object Detection
- Average Precision
- Linear SVM
- RPN
- multi task loss
- BiFPN
- Map
- YOLO
- Region proposal Network
- Darknet
- IOU
- detr
- Hungarian algorithm
- Non maximum suppression
- Object Detection metric
- herbwood
- AP
- Faster R-CNN
- hard negative mining
- Fast R-CNN
- Detection Transformer
- mean Average Precision
- Bounding box regressor
- object queries
- RoI pooling
- Anchor box
- Multi-task loss
- Today
- Total
약초의 숲으로 놀러오세요
RetinaNet 논문(Focal Loss for Dense Object Detection) 리뷰 본문
RetinaNet 논문(Focal Loss for Dense Object Detection) 리뷰
herbwood 2021. 2. 11. 10:36이번 포스팅에서는 RetinaNet 논문(Focal Loss for Dense Object Detection)을 리뷰해도록 하겠습니다. Object detection 모델은 이미지 내의 객체의 영역을 추정하고 IoU threshold에 따라 positive/negative sample로 구분한 후, 이를 활용하여 학습합니다. 하지만 일반적으로 이미지 내 객체의 수가 적기 때문에 positive sample(객체 영역)은 negative sample(배경 영역)에 비해 매우 적습니다. 이로 인해 positive/negative sample 사이에 큰 차이가 생겨 class imbalance 문제가 발생합니다.
class imbalance는 학습 시 두 가지 문제를 야기합니다. 첫 번째로 대부분의 sample이 easy negative, 즉 모델이 class를 예측하기 쉬운 sample이기 때문에 유용한 기여를 하지 못해 학습이 비효율적으로 진행됩니다. 두 번째로 easy negative의 수가 압도적으로 많기 때문에 학습에 끼치는 영향력이 커져 모델의 성능이 하락합니다.
Two-stage detector 계열의 모델은 이러한 문제를 해결하기 위해 두 가지 측면에서의 해결책을 적용했습니다. 첫 번째로 two-stage cascade, 즉 region proposals를 추려내는 방법을 적용하여 대부분의 background sample을 걸러주는 방법을 사용했습니다. 이에 대한 예시로 selective search, edgeboxes, deepmask, RPN 등이 있습니다. 두 번째로 positive/negative sample의 수를 적절하게 유지하는 sampling heuristic 방법을 적용했습니다. hard negative mining, OHEM 등이 이러한 방법에 해당합니다.
하지만 위에서 언급된 two-stage detector에서의 class imbalance 문제를 해결하는 방법은 one-stage detector에 적용하기 어렵습니다. one-stage detector는 region proposal 과정이 없어 전체 이미지를 빽빽하게 순회하면서 sampling하는 dense sampling 방법을 수행하기 때문에 two-stage detector에 비해 훨씬 더 많은 후보 영역을 생성합니다. 다시 말해 class imbalance 문제가 two-stage detector보다 더 심각합니다. 기존의 sampling heuristic 방법을 적용해도 여전히 배경으로 쉽게 분류된 sample이 압도적으로 많기 때문에 학습이 비효율적으로 진행됩니다.
본 논문에서는 학습 시 training imbalance가 주된 문제로 보고, 이러한 문제를 해결하여 one-stage detector에서 적용할 수 있는 새로운 loss function을 제시합니다.
Preview

본 논문에서는 Focal loss라는 새로운 loss function을 제시합니다. Focal loss는 cross entropy loss에 class에 따라 변하는 동적인 scaling factor를 추가한 형태를 가집니다. 이러한 loss function을 통해 학습 시 easy example의 기여도를 자동적으로 down-weight하며, hard example에 대해서 가중치를 높혀 학습을 집중시킬 수 있습니다. Focal loss의 효과를 실험하기 위해 논문에서는 one-stage detector인 RetinaNet을 설계합니다. 해당 네트워크는 ResNet-101-FPN을 backbone network로 가지며 anchor boxes를 적용하여 기존의 two-stage detector에 비해 높은 성능을 보여줍니다.
Main Ideas
Focal Loss
Focal loss는 one-stage detector 모델에서 foreground와 background class 사이에 발생하는 극단적인 class imbalance(가령 1:1000)문제를 해결하는데 사용됩니다. Focal loss는 이진 분류에서 사용되는 Cross Entropy(이하 CE) loss function으로부터 비롯됩니다.
CE loss
이진 분류에서 사용되는 CE loss는 아래와 같습니다.
$$CE(p, y)=
\begin{cases}
-log(p), & \mbox{if }\mbox y=1 \\
-log(1-p), & \mbox otherwise
\end{cases}$$
$$p_t =
\begin{cases}
p, & \mbox{if }\mbox y=1 \\
1-p, & \mbox otherwise
\end{cases}$$
$y \in [1, -1]$ : ground truth class
$p \in [0, 1]$ : 모델이 y=1이라고 예측한 확률
CE loss의 문제는 모든 sample에 대한 예측 결과를 동등하게 가중치를 둔다는 점입니다. 이로 인해 어떠한 sample이 쉽게 분류될 수 있음에도 불구하고 작지 않은 loss를 유발하게 됩니다. 많은 수의 easy example의 loss가 더해지면 보기 드문 class를 압도해버려 학습이 제대로 이뤄지지 않습니다.
Balanced Cross Entropy
이러한 문제를 해결하기 위해 가중치 파라미터인 $\alpha \in [0, 1]$를 곱해준 Balanced Cross Entropy가 등장합니다.
$$CE(p_t) = -\alpha log(p_t)$$
$y=1$일 때 $\alpha$를 곱해주고, $y=-1$일 때 $1-\alpha$를 곱해줍니다. 하지만 Balanced CE는 positive/negative sample 사이의 균형을 잡아주지만, easy/hard sample에 대해서는 균형을 잡지 못합니다. 논문에서는 Balanced Cross Entropy를 baseline으로 삼고 실험을 진행합니다.
Focal Loss
$$FL(p_t)=-(1-p_t)^{\gamma} log(p_t)$$
Focal loss는 easy example을 down-weight하여 hard negative sample에 집중하여 학습하는 loss function입니다. Focal loss는 modulating factor $(1-p_t)^\gamma$와 tunable focusing parameter $\gamma$를 CE에 추가한 형태를 가집니다.
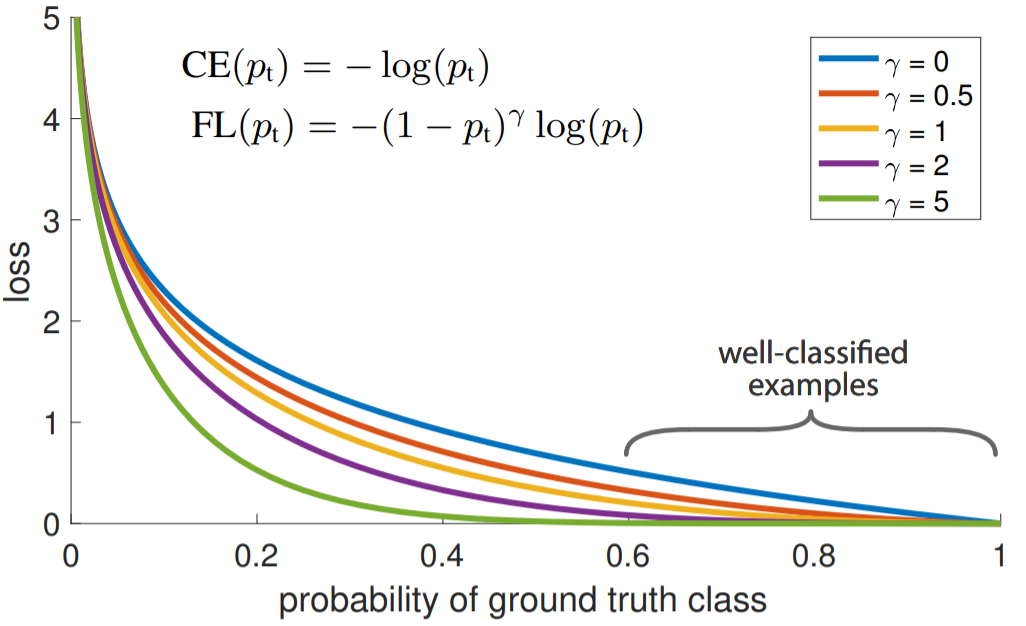

서로 다른 $\gamma \in [0, 5]$값에 따른 loss는 위의 도표를 통해 확인할 수 있습니다. 위의 도표에서 파란색 선은 CE를 의미합니다. 파란색 선은 경사가 완만하여 $p_t$가 높은 example과 낮은 example 사이의 차이가 크지 않다는 것을 확인할 수 있습니다. 반면 Focal loss는 focusing parameter $\gamma$에 따라 $p_t$가 높은 example과 낮은 example 사이의 차이가 상대적으로 크다는 것을 확인할 수 있습니다.
즉, y=1인 class임에도 $p_t$가 낮은 경우와, y=-1임에도 $p_t$가 높은 경우에 Focal loss가 높습니다. 반대의 경우에는 down-weight되어 loss값이 낮게 나타납니다. 이를 통해 Focal loss의 두 가지 특성을 확인할 수 있습니다.
1) $p_t$와 modulating factor와의 관계
example이 잘못 분류되고, $p_t$가 작으면, modulating factor는 1과 가까워지며, loss는 영향을 받지 않습니다. 반대로 $p_t$ 값이 크면 modulating factor는 0에 가까워지고, 잘 분류된 example의 loss는 down-weight됩니다.
2) focusing parameter $\gamma$의 역할
focusing parameter $\gamma$는 easy example을 down-weight하는 정도를 부드럽게 조정합니다. $\gamma=0$인 경우, focal loss는 CE와 같으며, $\gamma$가 상승할수록 modulating factor의 영향력이 커지게 됩니다. 논문에서는 실험 시 $\gamma=2$일 때 가장 좋은 결과를 보였다고 합니다.
직관적으로 봤을 때, modulating factor는 easy example의 기여도를 줄이고 example이 작은 loss를 받는 범위를 확장시키는 기능을 합니다. 예를 들어 $\gamma=2$, $p_t=0.9$일 때, CE에 비해 100배 적은 loss를 가집며, $p_t=0.968$일 때는 1000배 적은 loss를 가집니다. 이는 잘못 분류된 example을 수정하는 작업의 중요도를 상승시킴을 의미합니다.
RetinaNet
논문에서는 Focal loss를 실험하기 위해 RetinaNet이라는 one-stage detector를 설계합니다. RetinaNet은 하나의 backbone network와 각각 classification과 bounding box regression을 수행하는 2개의 subnetwork로 구성되어 있습니다. 자세한 설명은 RetinaNet의 학습 과정에서 살펴보도록 하겠습니다.
Training RetinaNet

1) Feature Pyramid by ResNet + FPN
먼저 이미지를 backbone network에 입력하여 서로 다른 5개의 scale을 가진 feature pyramid를 출력합니다. 여기서 backbone network는 ResNet 기반의 FPN(Feature Pyramid Network)를 사용합니다. pyramid level은 P3~P7로 설정합니다. feature pyramid에 대한 자세한 내용은 FPN 논문 리뷰 포스팅을 참고하시기 바랍니다.
- Input : image
- Process : feature extraction by ResNet + FPN
- Output : feature pyramid(P5~P7)
2) Classification by Classification subnetwork
1)번 과정에서 얻은 각 pyramid level별 feature map을 Classification subnetwork에 입력합니다. 해당 subnet는 3x3(xC) conv layer - ReLU - 3x3(xKxA) conv layer로 구성되어 있습니다. 여기서 K는 분류하고자 하는 class의 수를, A는 anchor box의 수를 의미합니다. 논문에서는 A=9로 설정합니다. 그리고 마지막으로 얻은 feature map의 각 spatial location(feature map의 cell)마다 sigmoid activation function을 적용합니다. 이를 통해 channel 수가 KxA인 5개(feature pyramid의 수)의 feature map을 얻을 수 있습니다.
- Input : feature pyramid(P5~P7)
- Process : classification by classification subnetwork
- Output : 5 feature maps with KxA channel
3) Bounding box regression by Bounding box regression subnetwork
1)번 과정에서 얻은 각 pyramid level별 feature map을 Bounding box regression subnetwork에 입력합니다. 해당 subnet 역시 classification subnet과 마찬가지로 FCN(Fully Convolutional Network)입니다. feature map이 anchor box별로 4개의 좌표값(x, y, w, h)을 encode하도록 channel 수를 조정합니다. 최종적으로 channel 수가 4xA인 5개의 feature map을 얻을 수 있습니다.
- Input : feature pyramid(P5~P7)
- Process : bounding box regression by bounding box regression subnet
- Output : 5 feature maps with 4xA channel
Inference
inference 시에는 속도를 향상시키기 위해 각 FPN의 pyramid level에서 가장 점수가 높은 1000개의 prediction만을 사용합니다. 2개의 subnetwork의 출력 결과에서 모든 level의 예측 결과는 병합되고, Non maximum suppression(threshold=0.5)를 통해 최종 예측 결과를 산출합니다.

RetinaNet을 COCO 데이터셋을 통해 학습시킨 후 서로 다른 loss function을 사용하여 AP 값을 측정했습니다. 그 결과 CE loss는 30.2%, Balanced Cross Entropy는 31.1%, Focal loss는 34% AP 값을 보였습니다. 또한 SSD 모델을 통해 positive/negative 비율을 1:3으로, NMS threshold=0.5로 설정한 OHEM과 성능을 비교한 결과, Focal loss를 사용한 경우의 AP값이 3.2% 더 높게 나타났습니다. 이를 통해 Focal loss가 class imbalance 문제를 기존의 방식보다 효과적으로 해결했습니다.
OHEM은 class imbalance 문제를 해결하기 위해 별도의 네트워크(readonly RoI network)를 설계한 반면, 본 논문에서는 loss function을 수정하는 비교적 단순한 방법으로 성능을 향상시켰다는 점에서 인상 깊었습니다. 다음 포스팅에서는 Mask R-CNN 논문을 읽고 리뷰해도록 하겠습니다.

Reference
'Computer Vision > Object Detection' 카테고리의 다른 글
| YOLO v3 논문(YOLOv3: An Incremental Improvement) 리뷰 (5) | 2021.02.15 |
|---|---|
| Mask R-CNN 논문(Mask R-CNN) 리뷰 (26) | 2021.02.14 |
| FPN 논문(Feature Pyramid Networks for Object Detection) 리뷰 (9) | 2021.01.27 |
| YOLO v2 논문(YOLO9000:Better, Faster, Stronger) 리뷰 (2) | 2021.01.15 |
| R-FCN 논문(R-FCN: Object Detection via Region-based Fully Convolutional Networks) 리뷰 (0) | 2021.01.04 |



