
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- pytorch
- Multi-task loss
- RoI pooling
- Darknet
- Object Detection metric
- Hungarian algorithm
- R-CNN
- Linear SVM
- Object Detection
- Fast R-CNN
- Detection Transformer
- hard negative mining
- IOU
- Non maximum suppression
- Bounding box regressor
- Region proposal Network
- RPN
- fine tune AlexNet
- Anchor box
- detr
- herbwood
- mean Average Precision
- multi task loss
- Faster R-CNN
- YOLO
- AP
- object queries
- Average Precision
- Map
- BiFPN
- Today
- Total
약초의 숲으로 놀러오세요
M2Det 논문(M2Det: A Single-Shot Object Detector based on Multi-Level Feature PyramidNetwork) 리뷰 본문
M2Det 논문(M2Det: A Single-Shot Object Detector based on Multi-Level Feature PyramidNetwork) 리뷰
herbwood 2021. 4. 4. 16:16이번 포스팅에서는 M2Det 논문(M2Det: A Single-Shot Object Detector based on Multi-Level Feature PyramidNetwork)을 읽고 리뷰해보도록 하겠습니다. 본 논문에서는 multi-scale feature map 생성을 위해 주로 사용되던 Feature Pyramid Network(이하 FPN)의 두 가지 한계에 대해 지적합니다.

- FPN은 classification task를 위해 설계된 backbone network로부터 feature map을 추출하는데, 이를 통해 구성된 feature pyramid는 object detection task를 수행하기 위해 충분히 representative하지 않습니다.
- Feature pyramid의 각 level의 feature map은 주로 backbone network의 single-level layer로부터 구성되었고, 이로 인해 객체의 외형에 따른 인식 성능의 차이가 발생합니다.
논문에서는 2)에 대하여 부연 설명합니다. 일반적으로 네트워크의 더 깊은 layer의 high-level feature는 classification task에 적합하고, 더 얕은 layer의 low-level feature는 localizatoin task에 적합합니다. 이 밖에도 전자는 복잡한 외형의 특징을 포착하는데 유리한 반면, 후자는 단순한 외형을 파악하는데 유리합니다.
현실의 데이터에서 비슷한 크기를 가지지만 객체에 대한 외형의 복잡한 정도는 상당히 다를 수가 있습니다. 가령 이미지에서 신호등과 멀리 있는 사람은 비슷한 크기를 가지지만 사람의 외형이 더 복잡합니다. 이 같은 경우에single-level feature map을 사용할 경우, 두 객체를 모두 포착하지 못할 수 있습니다.
본 논문에서는 위에서 언급한 문제를 해결하는 multi-scale, multi-level feature map을 사용하는 one-stage detector인 M2Det을 소개합니다.
Preview

본 논문에서는 서로 다른 크기와 외형의 복잡도를 가진 객체를 포착하기 위해 보다 효율적인 feature pyramid를 설계하는 네트워크인 MLFPN(Multi-Level Feature Pyramid Network)을 제시합니다. MLFPN은 세 가지 모듈로 구성되어 있습니다. 먼저 FFM(Feature Fusion Module)은 backbone network로부터 얕은 feature와 깊은 feature를 fuse(융합)하여 base feature를 생성합니다. TUM(Thinned U-shape Module)은 서로 다른 크기를 가진 feature map을 생성하고, FFMv2는 base feature와 이전 TUM의 가장 큰 scael의 feature map을 fuse하고, 그 다음 TUM에 입력합니다. 마지막으로 SFAM(Scale-wise Feature Aggregation Module)은 multi-level, multi-scale feature를 scale-wise feature concatenation과 channel-wise attention 매커니즘을 통해 집계합니다. 최종적으로 MLFPN과 SSD를 결합하여 M2Det이라는 강력한 end-to-end one-stage detector를 설계합니다.
Main Ideas
MLFPN(Multi-Level Feature Pyramid Network)
MLFPN(Multi-Level Feature Pyramid Network)은 multi-level, multi-scale feature map을 구성하는 네트워크로 3가지 모듈인, FFM(Feature Fusion Module), TUM(Thinned U-shape Module), SFAM(Scale-wise Feature Aggregation Module)로 구성되어 있습니다.
1) FFM(Feature Fusion Module)

FFM(Feature Fusion Module)은 네트워크에 있는 서로 다른 feature를 융합(fuse)하고, 이를 최종 multi-level feature pyramid를 설계하는데 중요한 역할을 합니다. FFM은 같은 역할을 수행하지만 서로 다른 구조를 가진 FFMv1과 FFMv2가 있습니다.
FFMv1은 backbone network로부터 두 개의 서로 다른 scale을 가지는 feature map을 추출한 후 융합하여 base feature map을 생성합니다. 그림 (a)과 같이 각각의 feature map에 conv 연산을 적용하고, scale이 작은 feature map을 upsample시켜준 후 concat하여 하나의 feature map을 얻습니다. 여기서 두 개의 feature map은 각각 얕은 layer와 깊은 layer에서 추출되었기 때문에 풍부한 semantic 정보(high-level + low-level features)를 MLFPN에 제공하게 됩니다.
FFMv2는 FFMv1이 생성한 base feature에 대하여 conv 연산을 적용한 후 이전 TUM의 가장 큰 scale의 feature map을 입력 받아 concat한 후 다음 TUM에 전달합니다. 그림 (b)와 같이 동작합니다. 이 때, 입력으로 사용하는 두 feature map의 scale이 같음을 알 수 있습니다. TUM에 대한 설명은 아래에서 바로 살펴보도록 하겠습니다.
2) TUM(Thinned U-shape Module)
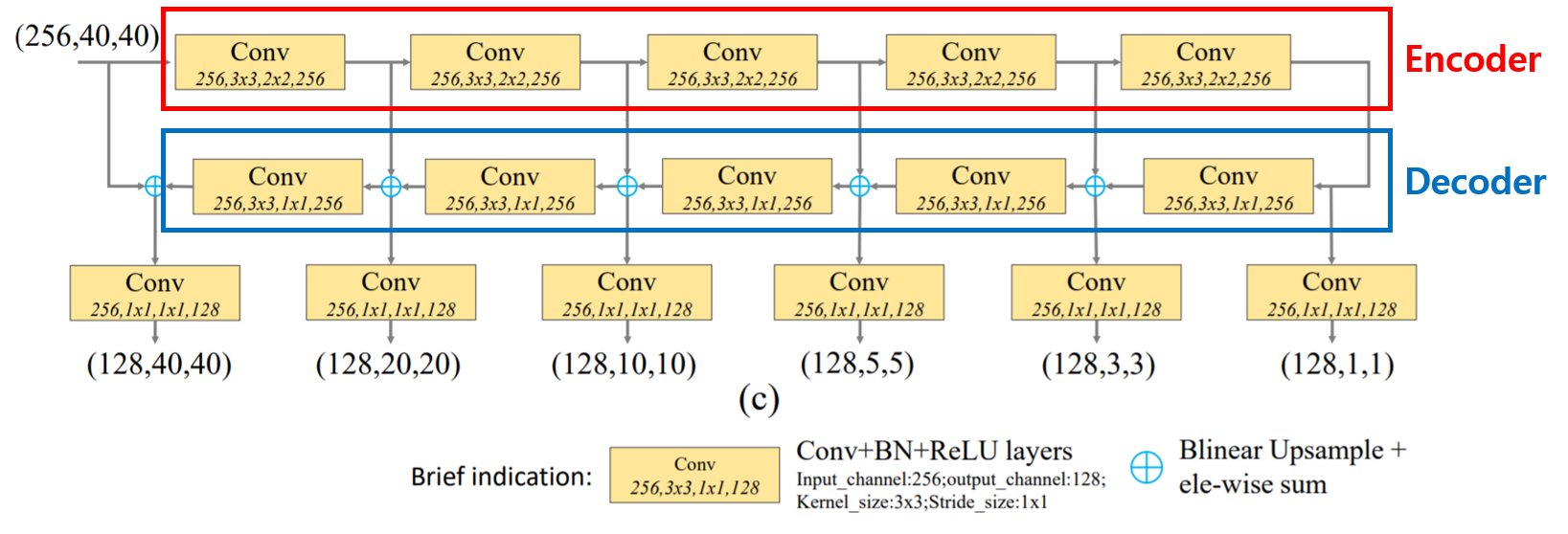
TUM(Thinned U-shape Module)은 입력받은 feature map에 대하여 multi-level feature map을 생성하는 역할을 수행하며, Encoder-Decoder 구조로 U자형 구조를 가집니다.
Encoder network에서는 입력받은 feature map에 대하여 3x3 conv(stride=2) 연산을 적용하여 scale이 다른 다수의 feature map({E1, E2, E3, E4, E5})을 출력합니다.
Decoder network에서는 Encoder network에서 출력한 다수의 feature map에 대하여 더 높은 level(scale이 더 작은)에 대하여 upsample한 후 바로 아래 level의 feature map과 element-wise하게 더해준 후 1x1 conv 연산을 수행합니다. 이를 통해 최종적으로 scale이 다른 다수의 feature map({D1, D2, D3, D4, D5, D6})을 출력합니다.

MLFPN 내부에서 TUM은 FFM과 서로 교차하는 구조를 가집니다. FFMv1에서 얻은 base feature map을 첫 번째 TUM에 입력하여 feature map({D1, D2, D3, D4, D5, D6})을 얻습니다. TUM의 출력 결과 중 scale이 가장 큰 feature map과 base feature map을 FFMv2를 통해 fuse한 후 두 번째 TUM에 입력하고, 이러한 과정을 반복합니다. 논문에서는 총 8개의 TUM을 사용했습니다.
각각의 TUM의 Decoder network의 출력 결과는 입력으로 주어진 feature map의 level에 대한 multi-scale feature map에 해당합니다. 전체 TUM에 대해 봤을 때, 축적된 모든 TUM의 feature map은 multi-level, multi-scale feature를 형성하게됩니다. 즉, 초반의 TUM은 shallow-level feature, 중간의 TUM은 medium-level feature, 후반의 TUM은 deep-level feature를 제공합니다.
3) SFAM(Scale-wise Feature Aggregation Module)
SFAM(Scale-wise Feature Aggregation Module)은 TUMs에 의해 생성된 multi-level, multi-scale featue를 scale-wise feature concatenation과 channel-wise attention 매커니즘을 통해 집계하여 multi-level feature pyramid로 구성하는 역할을 수행합니다.

1) Scale-wise feature concatenation
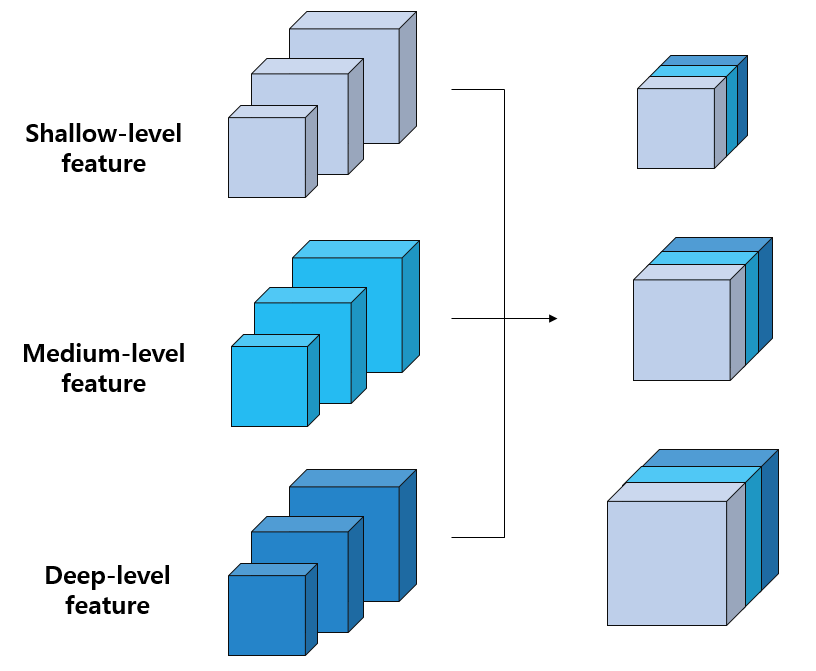
Scale-wise feature concatenation 과정에서는 각각의 TUM으로부터 생성된 multi-level feature map을 같은 scale별로 concat하는 작업을 수행합니다. 각각의 TUM은 특정 level에 관련된 feature maps를 출력합니다. 위의 예시의 경우 3개의 TUM이 각각 shallow-level, medium-level, deep-level features를 생성했습니다. 각 level의 feature maps는 3개의 서로 다른 scale의 feature map으로 구성되어 있습니다. 여기서 같은 scale을 가지는 feature map끼리 concat해줌으로써, 서로 다른 level을 가지는 같은 scale의 feature map이 3개가 생성됩니다.
실제 논문에서는 8개의 TUM에서 각각 6개의 서로 다른 scale의 feature map을 출력한다고 합니다. 따라서 실제 Scale-wise feature concatenation 과정을 수행하면, 서로 다른 level에 대한 정보를 함축한 8개의 feature map이 결합되어, 최종적으로 6개의 multi-level, multi-scale feature map을 출력하게 됩니다.
2) Channel-wise attention
논문에서는 단순히 Scale-wise feature concatenation만으로는 충분히 적용 가능(adaptive)하지 않다고 언급합니다. Channel-wise attention 모듈은 feature가 가장 많은 효율을 얻을 수 있는 channel에 집중(attention)하도록 설계하는 작업을 수행합니다. 본 모듈에서는 Scale-wise feature concatenation 과정에서 출력한 feature map을 SE(Squeeze Excitation) block에 입력합니다. 여기서 SE block에 대해서 가볍게 살펴보고 넘어가도록 하겠습니다.

SE(Squeeze Excitation) block은 CNN에 부착하여 사용할 수 있는 블록으로, 연산량을 크게 늘리지 않으면서 정확도를 향상시킵니다. SE block은 Squeeze step, Excitation step, Recalibration step으로 구성되어 있습니다.
- Squeeze step : 입력으로 들어온 HxWxC 크기의 feature map에 대하여 Global Average Pooling을 수행합니다. 이를 통해 각 channel을 하나의 숫자로 표현하는 것이 가능합니다.
- Excitation step : 앞서 얻은 1x1xC 크기의 feature map에 대하여 2개의 fc layer를 적용하여 channel별 상대적 중요도를 구합니다. 이 때 두 번째 fc layer의 activation function을 sigmoid로 지정합니다. 이를 통해 최종 output은 0~1 사이 값을 가져 channel별 중요도를 파악하는 것이 가능합니다.
- Recalibration step : 앞선 과정에서 구한 channel별 중요도와 원본 feature map을 channel별로 곱해줘 channel별로 중요도를 재보정(recalibrate)해줍니다.
Channel-wise attention 과정에서는 TUM이 출력한 multi-level, multi-scale feature map를 SE block에 입력하여 feature map의 channel별 중요도를 재보정하였습니다.
Training M2Det

1) Extract two feature maps from backbone network
먼저 backbone network로부터 서로 다른 level에서 서로 다른 scale을 가진 두 개의 feature map을 추출합니다. 여기서 backbone network로는 VGG 혹은 ResNet을 사용합니다.
- Input : image
- Process : extract two feature maps
- Output : two feature maps within different scales
2) Generate Base feature map by FFMv1
앞서 얻은 두 개의 feature map을 FFMv1 모듈을 통해 융합(fuse)하여 하나의 Base feature map을 생성합니다.
- Input : two feature maps within different scales
- Process : fuse two feature maps
- Output : Base feature map
3) Generate Multi-level, Multi-scale feature maps by jointly alternating FFMv2 and TUM
Base feature map을 첫 번째 TUM에 입력하여 multi-level, multi-scale feature map을 얻습니다. 그리고 첫 번째 TUM에서 얻은 feature map 중에서 가장 scale이 큰 feature map과 base feature map을 FFMV2를 통해 융합(fuse)합니다. 이후 융합된 feature map을 두 번째 TUM에 입력합니다.
논문에서는 TUM의 수를 8개로 설정했기 때문에 위의 과정을 반복하여 총 8개의 multi-level, multi-scale feature maps를 얻습니다.
- Input : Base feature map
- Process : Iterate through FFMv2s and TUMs
- Output : 8 Multi-level, Multi-scale feature maps
4) Construct Final Feature pyramid by SFAM
앞서 얻은 8개의 multi-level, multi-scale feature maps를 Scale-wise feature concatenation 과정을 통해 scale별로 feature map을 결합합니다. 이후 결합된 각각의 feature map을 SE block에 입력하여 재보정된 6개의 feature map으로 구성된 Feature pyramid를 얻습니다(논문에서는 feature pyramid의 scale을 6개로 지정했습니다).
- Input : 8 Multi-level, Multi-scale feature maps
- Process : Scale-wise feature concatenation and Channel-wise attention
- Output : Feature pyramid with 6 recalibrated feature maps
5) Prediction by classification branch and bbox regression branch
Feature pyramid 각 level별 feature map을 두 개의 병렬로 구성된 conv layer에 입력하여 class score와 bbox regressor를 얻습니다.
- Input : Feature pyramid with 6 recalibrated feature maps
- Process : classification and bbox regression
- Output : 6 class scores and bbox regressors
Detection
실제 detection 시에는 네트워크에서 예측한 bounding box에 대하여 Soft-NMS를 적용하여 최종 prediction을 출력합니다.

M2Det은 MS COCO 데이터셋을 통해 실험한 결과, pytorch 최적화 기능을 수행하여 15.8 FPS라는 속도를 달성했습니다. 또한 AP값은 44.2%를 보이면 당시 모든 one-stage detector의 성능을 뛰어넘는 놀라운 결과를 보였습니다.

M2Det의 가장 큰 기여는 다름 아니라 multi-scale뿐만 아니라 multi-level로 구성된 Feature pyramid를 설계했다는 점이라고 생각합니다. Mutli-level feature는 앞서 언급한 바와 같이 객체의 외형(appearance)가 복잡한 상황을 처리하는데 유용하게 사용될 수 있다는 장점이 있습니다.
논문에서는 다양한 scale과 외형 변화를 잘 포착할 수 있음을 파악하기 위해 classification 시, feature map의 activation value를 살펴보았습니다. 우의 입력 이미지를 보면 사람 객체 2개, 차 객체 2개, 신호등 1개를 포함하고 있습니다. 여기서 사람 객체끼리, 그리고 차 객체끼리 서로 크기가 다릅니다. 그리고 신호등은 작은 사람, 작은 차와 비슷한 크기입니다. 위의 객체에 대한 활성화 정도를 통해 알 수 있는 사실은 다음과 같습니다.
- 작은 사람과 작은 차는 큰 크기의 feature map에서 강한 활성화 정도를 보이는 반면, 큰 사람과 큰 차는 작은 크기의 feature map에서 강한 활성화 정도를 보입니다. 이는 multi-scale feature가 객체의 크기를 잘 포착하고 있음을 나타냅니다.
- 신호등, 작은 사람, 작은 차는 같은 크기의 feature map에서 큰 activation value를 가집니다. 이는 세 객체가 서로 비슷한 크기를 가지고 있기 때문입니다.
- 사람, 차, 신호등은 highest-level, middle-level, lowest-level feature map에서 가장 큰 activation value를 가집니다. 이는 객체의 외형의 복잡도를 multi-level feature가 잘 포착하고 있음을 의미합니다.
즉 위의 예시를 통해 M2Det은 객체의 크기와 외형의 복잡도라는 특징을 잘 포착하고 있음을 알 수 있습니다.
지금까지 hoya님의 Object detection 추천 논문 리스트의 빨간 글씨로 써진 논문을 전부 다 리뷰했습니다. 시간이 좀 걸렸지만 19년도까지의 Object detection 분야의 핵심적인 논문을 읽어봄으로써 해당 논문의 지식뿐만 아니라 여러 가지를 얻을 수 있었습니다. 먼저 많지는 않지만 15편의 논문을 읽으면서 논문을 어떤 식으로 읽으면 좋은지 감이 온 것 같습니다. 중요한 부분과 짚고 넘어갈 부분을 어느 정도 구분할 수 있게 되면서 조금 더 효율적으로 논문을 읽고 정리할 수 있게 된 것 같습니다. 물론 아직도 멀었습니다🤣. 그리고 Object detection 분야의 핵심적인 논문을 읽음으로써 관련된 논문이나 파생된 논문을 상대적으로 빠르게 이해할 수 있게 되었습니다. Object detection 분야를 공부하기 위한 코어를 단단하게 다질 수 있었던 좋은 경험이었습니다. 그리고 5년간 발표된 논문들을 읽으면서 이 분야가 어떤 방향으로 발전해왔는지, 역사의 흐름을 어느 정도 파악하게 되었습니다. 이러한 관점은 향후 제가 연구 주제를 정할 때 큰 도움이 되리라고 생각합니다. Object detection을 공부하기 위한 좋은 이정표를 제시해주신 hoya님께 진심으로 감사드립니다.
다음 포스팅부터는 20년도에 나온 핵심 Object detection 논문과 제가 공부하면서 읽은 몇 편의 논문에 대한 리뷰를 올리도록 하겠습니다. 아래와 같이 기존의 paper list에 20년도 이후부터 제가 생각한 must read object detection 논문을 추가했습니다(22.12.13 Updated). 혹시나 추가해야하거나 추천하는 논문이 있으면 댓글 달아주세요!

Reference
M2Det 논문(M2Det: A Single-Shot Object Detector based on Multi-Level Feature PyramidNetwork)
'Computer Vision > Object Detection' 카테고리의 다른 글
| EfficientDet 논문(EfficientDet: Scalable and Efficient Object Detection) 리뷰 (0) | 2022.12.12 |
|---|---|
| YOLO v4 논문(YOLOv4: Optimal Speed and Accuracy of Object Detection) 리뷰 (7) | 2021.07.18 |
| RefineDet 논문(Single-Shot Refinement Neural Network for Object Detection) 리뷰 (2) | 2021.03.22 |
| YOLO v3 논문(YOLOv3: An Incremental Improvement) 리뷰 (5) | 2021.02.15 |
| Mask R-CNN 논문(Mask R-CNN) 리뷰 (26) | 2021.02.14 |



